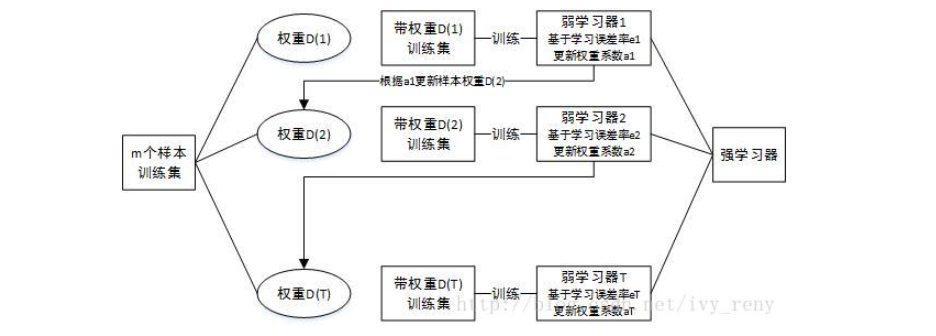
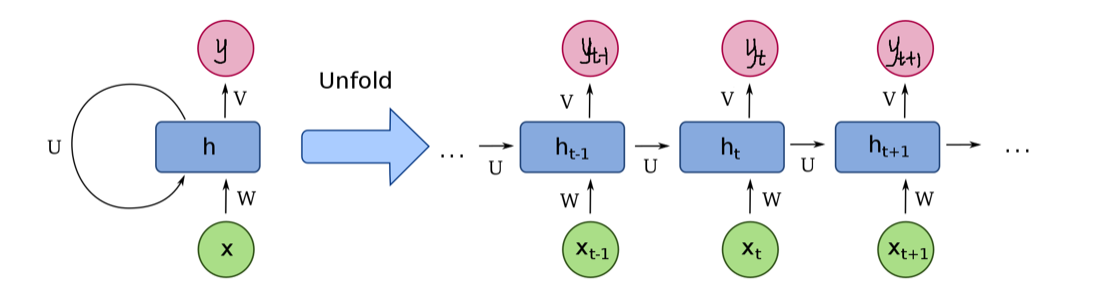
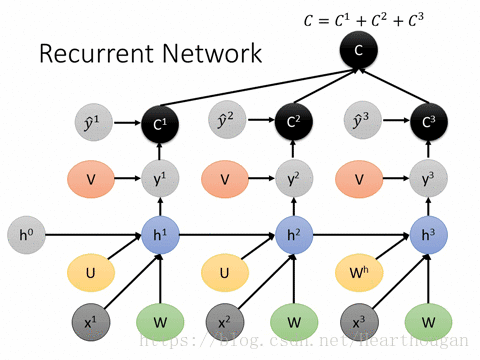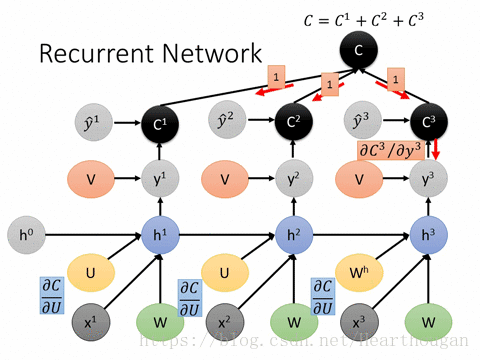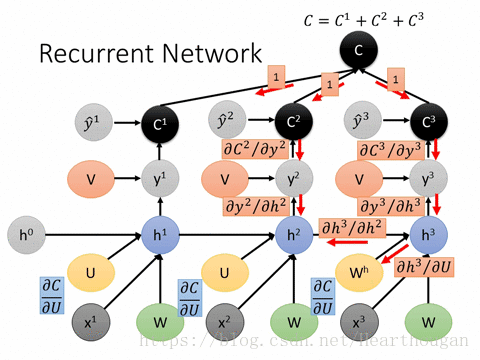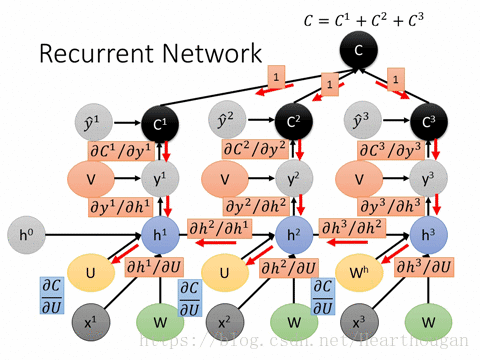
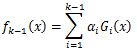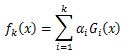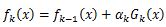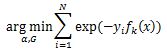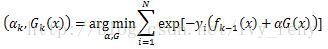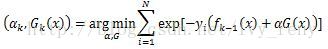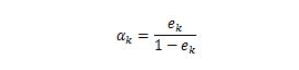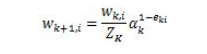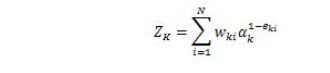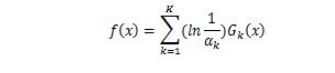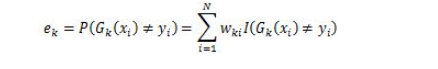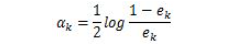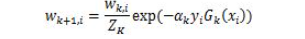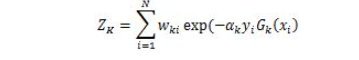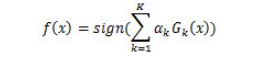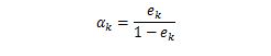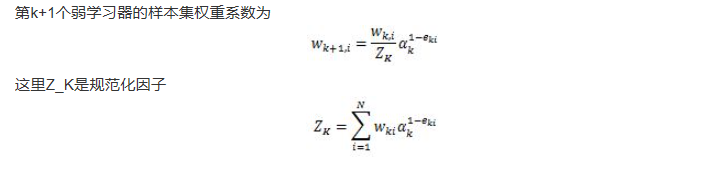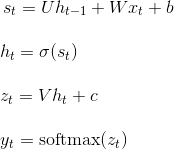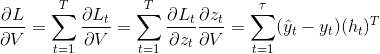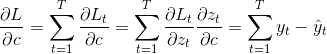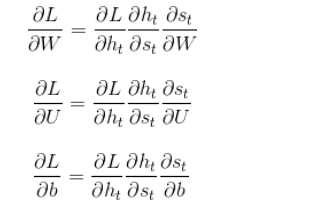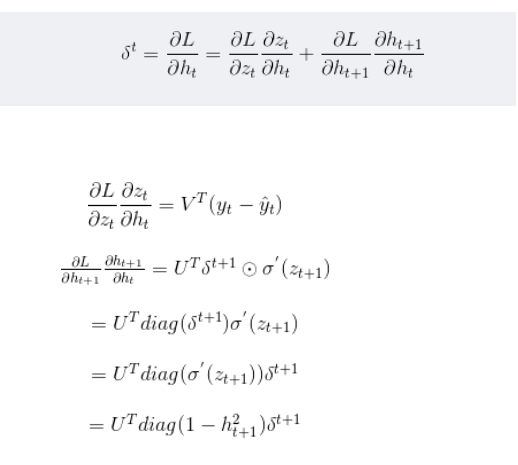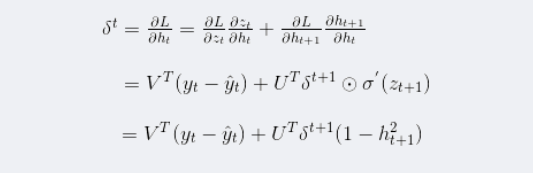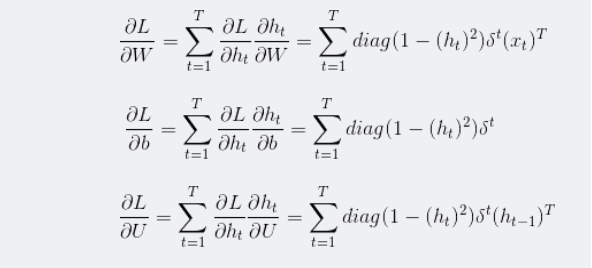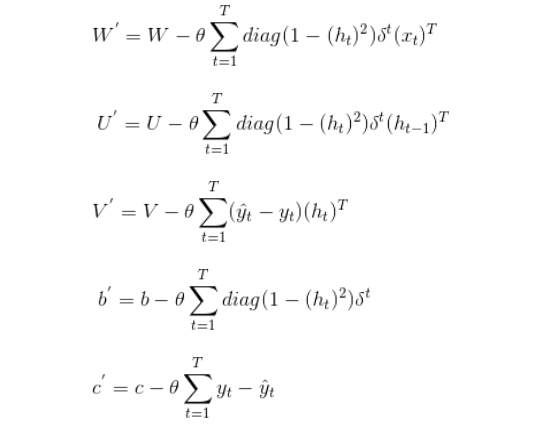OpenCV:二值化操作cv2.threshold函数
(一)简单阈值
简单阈值当然是最简单,选取一个全局阈值,然后就把整幅图像分成了非黑即白的二值图像了。函数为cv2.threshold()
这个函数有四个参数,第一个原图像,第二个进行分类的阈值,第三个是高于(低于)阈值时赋予的新值,第四个是一个方法选择参数,常用的有:
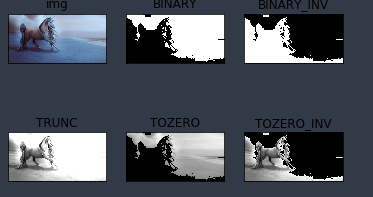
• cv2.THRESH_BINARY(黑白二值)
• cv2.THRESH_BINARY_INV(黑白二值反转)
• cv2.THRESH_TRUNC (得到的图像为多像素值)
• cv2.THRESH_TOZERO
• cv2.THRESH_TOZERO_INV
该函数有两个返回值,第一个ret(得到的阈值值(在后面一个方法中会用到)),第二个就是阈值化后的图像。
一个实例如下:
1 | import cv2 |
1 | gray=cv2.cvtColor(image,cv2.COLOR_BGR2GRAY) |
(二)自适应阈值
前面看到简单阈值是一种全局性的阈值,只需要规定一个阈值值,整个图像都和这个阈值比较。而自适应阈值可以看成一种局部性的阈值,通过规定一个区域大小,比较这个点与区域大小里面像素点的平均值(或者其他特征)的大小关系确定这个像素点是属于黑或者白(如果是二值情况)。使用的函数为:cv2.adaptiveThreshold()
该函数需要填6个参数:
第一个原始图像
第二个像素值上限
第三个自适应方法Adaptive Method:
—cv2.ADAPTIVE_THRESH_MEAN_C:领域内均值
—cv2.ADAPTIVE_THRESH_GAUSSIAN_C :领域内像素点加权和,权 重为一个高斯窗口第四个值的赋值方法:只有cv2.THRESH_BINARY 和cv2.THRESH_BINARY_INV
第五个Block size:规定领域大小(一个正方形的领域)
第六个常数C,阈值等于均值或者加权值减去这个常数(为0相当于阈值 就是求得领域内均值或者加权值)
这种方法理论上得到的效果更好,相当于在动态自适应的调整属于自己像素点的阈值,而不是整幅图像都用一个阈值。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15import cv2
import matplotlib.pyplot as plt
img=cv2.imread("h.jpg")
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
#全局阈值
ret,th1=cv2.threshold(gray,127,255,cv2.THRESH_BINARY)
#自适应阈值
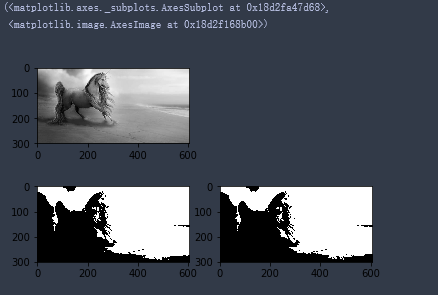
th2=cv2.adaptiveThreshold(gray,255,cv2.ADAPTIVE_THRESH_MEAN_C,cv2.THRESH_BINARY,11,2)
th3=cv2.adaptiveThreshold(gray,255,cv2.ADAPTIVE_THRESH_GAUSSIAN_C,cv2.THRESH_BINARY,11,2)
images=[gray,th1,th2,th3]
plt.figure()
for i in range(4):
plt.subplot(2,2,i+1),plt.imshow(images[i],'gray')
plt.show()
(三)Otsu’s二值化
有的图像可能阈值不是127得到的效果更好。那么这里我们需要算法自己去寻找到一个阈值,而Otsu’s就可以自己找到一个认为最好的阈值。并且Otsu’s非常适合于图像灰度直方图(灰度直方图是反映一幅图像中各灰度级像素出现的频率与灰度级的关系,以灰度级为横坐标,频率为纵坐标,绘制频率同灰度级的关系图像就是一幅灰度图像的直方图)具有双峰的情况,他会在双峰之间找到一个值作为阈值,对于非双峰图像,可能并不是很好用。那么经过Otsu’s得到的那个阈值就是函数cv2.threshold的第一个参数了。因为Otsu’s方法会产生一个阈值,那么函数cv2.threshold的的第二个参数(设置阈值)就是0了,并且在cv2.threshold的方法参数中还得加上语句cv2.THRESH_OTSU。图像的灰度统计图中可以明显看出只有两个波峰就是双峰图像,比如下面一个图的灰度直方图就可以是双峰图:
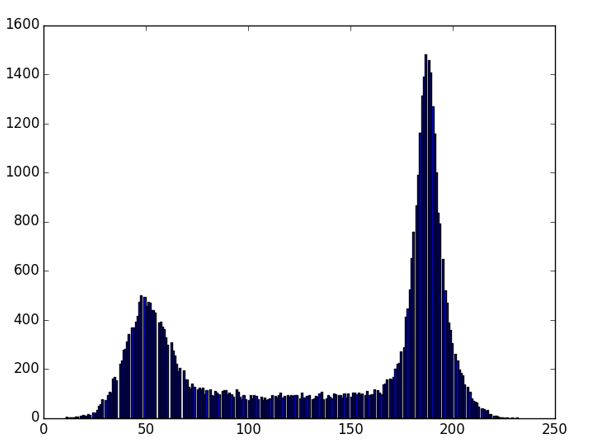
绘制灰度直方图:
1 | import matplotlib.pyplot as plt |
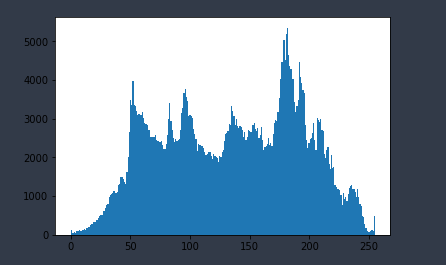
这里所用的实例不具有明显的双峰,所以可能效果不好
1 | import cv2 |
 距离相应的表示为:
距离相应的表示为:

 下求w的L2范数的最小值。
下求w的L2范数的最小值。 ,m是数据集的个数,R为算法参数,其约束条件变为:
,m是数据集的个数,R为算法参数,其约束条件变为: ,可以把ε理解为样本x(i)违反一大间距规则的程度。针对大多数满足约束条件的样本ε=0。而对部分违反最大间距规则的样本ε>0。参数R则表示对违反约束的样本的”惩罚”。R越大对违反约束的点“惩罚力度”越大反之越小 。这样模型就会倾向于允许部分点违反最大间距规则。可以纠正过拟合问题
,可以把ε理解为样本x(i)违反一大间距规则的程度。针对大多数满足约束条件的样本ε=0。而对部分违反最大间距规则的样本ε>0。参数R则表示对违反约束的样本的”惩罚”。R越大对违反约束的点“惩罚力度”越大反之越小 。这样模型就会倾向于允许部分点违反最大间距规则。可以纠正过拟合问题


 预测函数中也包含x(i)^Tx(j),引入K(x^(i),x(j))=x(i)^Tx(j)作为核函数,白哦是两个向量的相似性,如向量垂直时,就表示两个向量线性无关,值为0,引入核函数后预测函数变为:
预测函数中也包含x(i)^Tx(j),引入K(x^(i),x(j))=x(i)^Tx(j)作为核函数,白哦是两个向量的相似性,如向量垂直时,就表示两个向量线性无关,值为0,引入核函数后预测函数变为: