图解为什么会产生维数灾难
假如数据集包含10张照片,照片中包含三角形和圆两种形状。现在来设计一个分类器进行训练,让这个分类器对其他的照片进行正确分类(假设三角形和圆的总数是无限大),简单的,我们用一个特征进行分类:
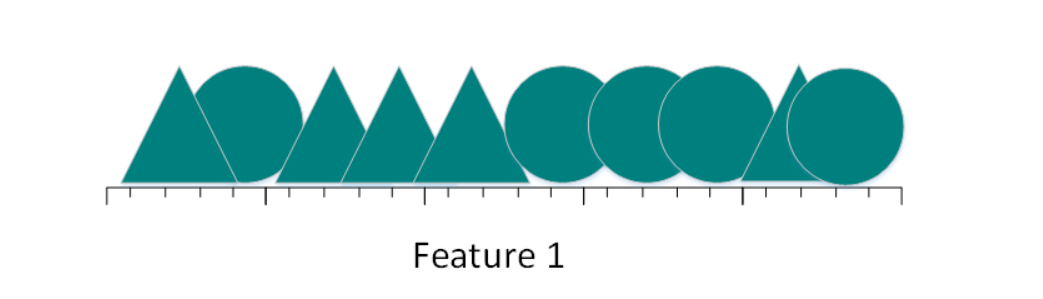
图a
从上图可看到,如果仅仅只有一个特征进行分类,三角形和圆几乎是均匀分布在这条线段上,很难将10张照片线性分类。那么,增加一个特征后的情况会怎么样:
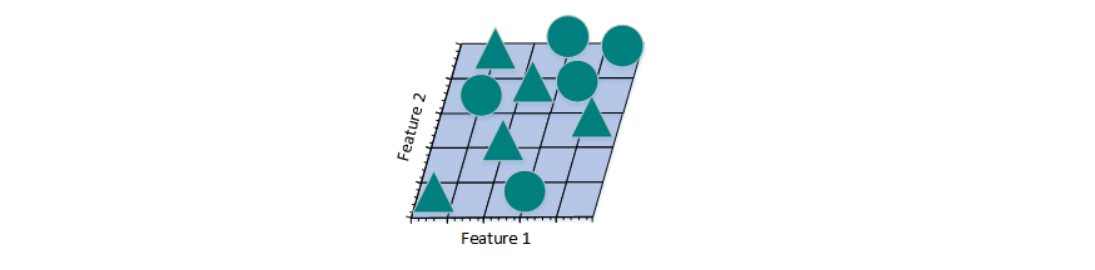
图b
增加一个特征后,我们发现仍然无法找到一条直线将三角形和圆形分开。所以,考虑需要再增加一个特征:
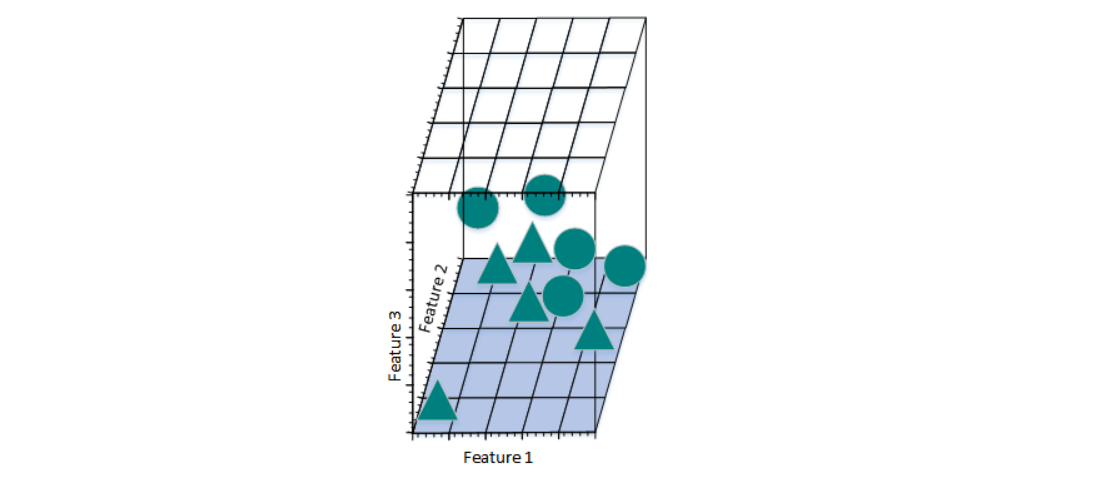
图c
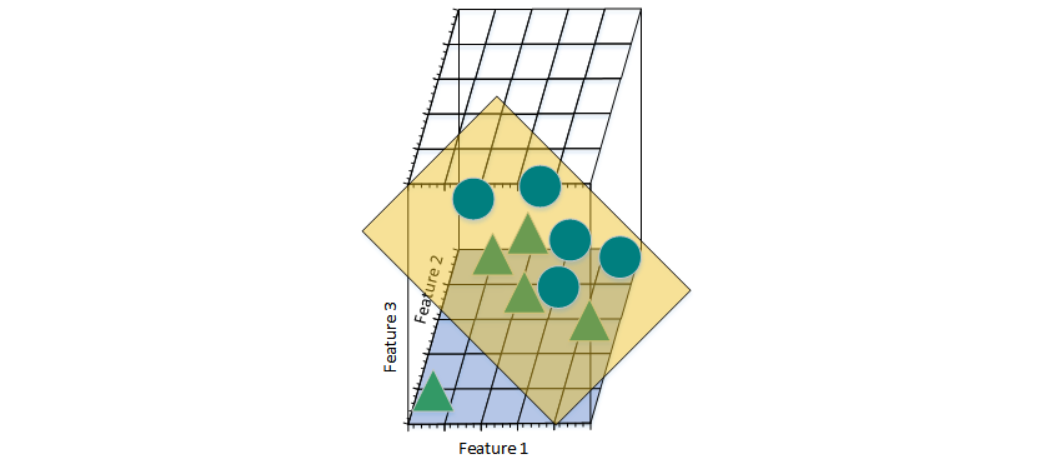
图d
此时,可以找到一个平面将三角形和圆分开。
计算不同特征数是样本的密度:
(1)一个特征时,假设特征空间时长度为5的线段,则样本密度为10/5 = 2。
(2)两个特征时,特征空间大小为5 * 5 = 25,样本密度为10/25 = 0.4。
(3)三个特征时,特征空间大小是5 5 5 = 125,样本密度为10 / 125 = 0.08。
以此类推,如果继续增加特征数量,样本密度会越来越稀疏,此时,更容易找到一个超平面将训练样本分开。当特征数量增长至无限大时,样本密度就变得非常稀疏。
将高维空间的分类结果映射到低维空间时:
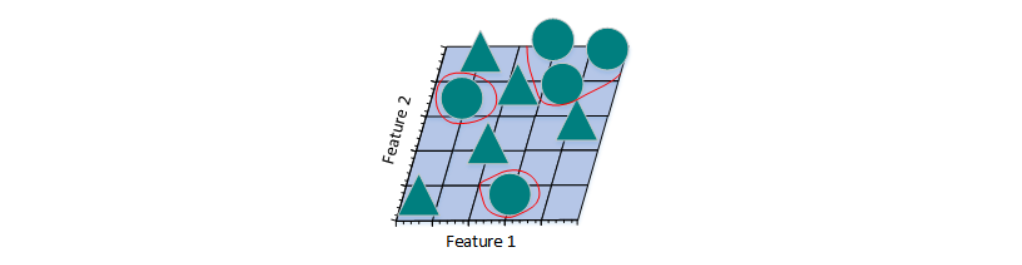
图e
上图是将三维特征空间映射到二维特征空间后的结果。尽管在高维特征空间时训练样本线性可分,但是映射到低维空间后,结果正好相反。事实上,增加特征数量使得高维空间线性可分,相当于在低维空间内训练一个复杂的非线性分类器。不过,这个非线性分类器太过“聪明”,仅仅学到了一些特例。如果将其用来辨别那些未曾出现在训练样本中的测试样本时,通常结果不太理想,会造成过拟合问题。
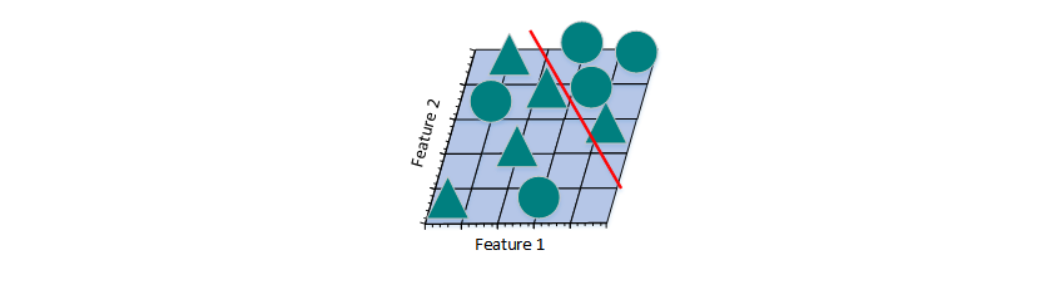
图f
上图所示的只采用2个特征的线性分类器分错了一些训练样本,准确率似乎没有图e的高,但是,采用2个特征的线性分类器的泛化能力比采用3个特征的线性分类器要强。因为,采用2个特征的线性分类器学习到的不只是特例,而是一个整体趋势,对于那些未曾出现过的样本也可以比较好地辨别开来。换句话说,通过减少特征数量,可以避免出现过拟合问题,从而避免“维数灾难”。
从另一个角度看维数灾难
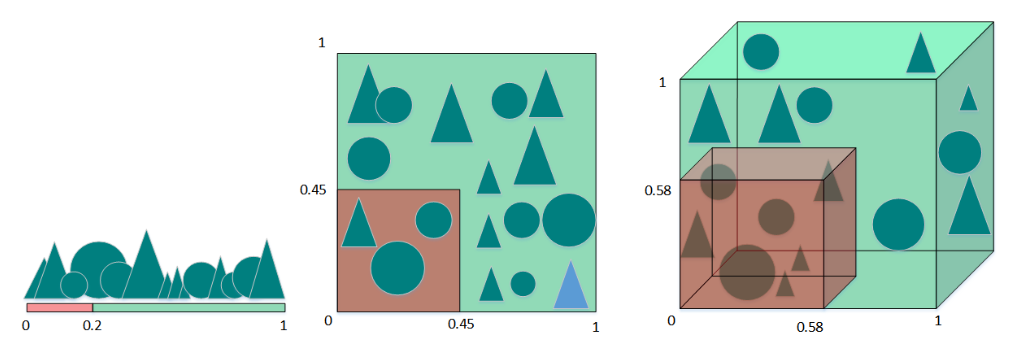
假设只有一个特征时,特征的值域是0到1,每一个三角形和圆的特征值都是唯一的。如果我们希望训练样本覆盖特征值值域的20%,那么就需要三角形和圆总数的20%。我们增加一个特征后,为了继续覆盖特征值值域的20%就需要三角形和圆总数的45%(0.452的平方约等于0.2)。继续增加一个特征后,需要三角形和圆总数的58%(0.583的三次方约等于0.2)。随着特征数量的增加,为了覆盖特征值值域的20%,就需要更多的训练样本。如果没有足够的训练样本,就可能会出现过拟合问题。
通过上述例子,我们可以看到特征数量越多,训练样本就会越稀疏,分类器的参数估计就会越不准确,更加容易出现过拟合问题。“维数灾难”的另一个影响是训练样本的稀疏性并不是均匀分布的。处于中心位置的训练样本比四周的训练样本更加稀疏。
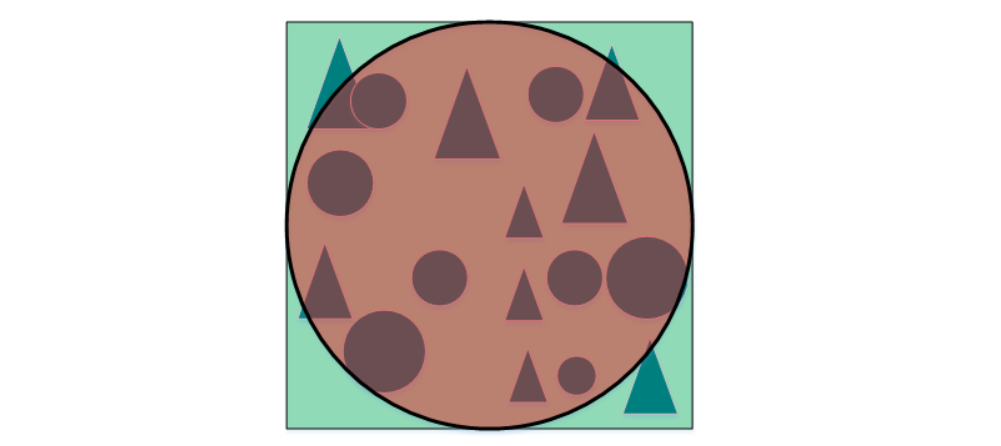
假设有一个二维特征空间,如上图所示的矩形,在矩形内部有一个内切的圆形。由于越接近圆心的样本越稀疏,因此,相比于圆形内的样本,那些位于矩形四角的样本更加难以分类。当维数变大时,特征超空间的容量不变,但单位圆的容量会趋于0,在高维空间中,大多数训练数据驻留在特征超空间的角落。散落在角落的数据要比处于中心的数据难于分类。
怎样避免维数灾难
解决维度灾难问题:
主成分分析法PCA,线性判别法LDA
奇异值分解简化数据、拉普拉斯特征映射
Lassio缩减系数法、小波分析法等。