一、集成学习概述
集成学习通过构建并结合多个学习器来完成学习任务。通过将多个学习器结合,常可以获得比单一学习器显著优越的泛化性能,达到博采众长的目的。
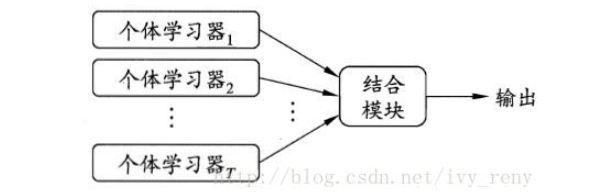
- 集成学习有两个主要的问题需要解决:
1、如何训练每个学习器?
2、如何融合各个学习器?
二、个体学习器
要获得好的学习器,个体学习器应“好而不同”,即个体学习器要有一定的准确性,并且要有多样性。
根据个体学习器包含的类型,可分为同质个体学习器和异质个体学习器。集成中可以只包含同种类型的个体学习器,如决策树、神经网络,这样的集成是同质的,同质集成中的个体学习器亦称“基学习器”,相应的学习算法称为“基学习算法”。集成也可以包含不同类型的个体学习器,如同时包含决策树和神经网络,这样的集成是异质的,个体学习器常称为“组件学习器”。目前同质个体学习器的应用岁最广泛的,一般提到集成学习都是指同质个体学习器,而同质个体学习器使用最多的模型是CART决策树和神经网络。
根据个体学习器的生成是否存在依赖关系,可以分为两类。个体学习器间存在强依赖关系,必须串行生成,代表算法是boosting系列算法;个体学习器之间不存在强依赖关系,可以并行生成,代表算法是bagging和随机森林系列算法
三.集成学习之Boosting
Boosting算法的工作机制是首先从训练集中用初始权重训练出一个弱学习器1,根据弱学习器的学习误差率来更新训练样本的权重,使弱学习器1学习误差率高的训练样本点的权重变高,在后面的弱学习器2中得到更多的重视,然后基于调整权重后的训练集来训练弱学习器2,如此重复,直到弱学习器数目达到事先指定的数目T,最后将T个弱学习器通过集合策略进行整合,得到最终的强学习器。从偏差-方差分解的角度看,Boosting主要关注降低偏差,因此Boosting能基于泛化性能相当弱的学习器构建出很强的集成。
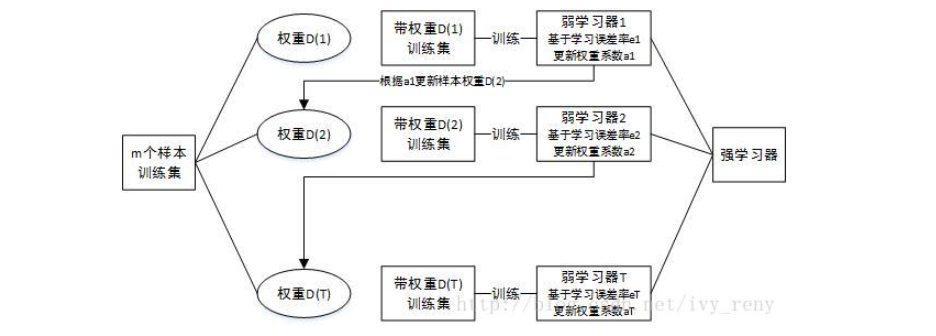
四.集成学习之Bagging
Bagging算法通过T次随机采样得到T个采样集,独立训练出T个弱学习器,再通过集合策略得到最终的强学习器。这里的随机采样一般采用自助采样法(Bootstrap sampling),即在包含m个样本的数据集中,每次随机取出一个样本放入采样集中,再把该样本放回原数据集中,这样下次采样时该样本仍有可能被选中,这样经过m次随机采样可以得到含m个样本的采样集。原训练集中有的样本在采样集中多次出现,有的从未出现,初始训练集中约63.2%的样本出现在采样集中。从偏差-方差分解的角度看,Bagging主要关注降低方差,因此在不剪枝决策树、神经网络等易受样本扰动的学习器上效果更为明显。
随机森林是Bagging的一个特化进阶版,特化是因为随机森林的弱学习器都是决策树,进阶是因为随机森林在Bagging的样本随机采样基础上,又加上了特征的随机选择,其基本思想没有脱离Bagging的范畴。
五.集成学习的结合策略
1.平均法
对于数值类的回归预测,通常使用平均法,也就是对T个弱学习器的输出进行平均得到最终的预测输出。通常有:
算术平均法
加权平均法
2.投票法
对于分类问题的预测,通常使用投票法。假设预测类别是{c1,c2,c3……ck}
相对多数投票法
1
最简单的投票法,也就是常说的少数服从多数,T个弱学习器对样本的预测中,数量最多的类别作为最终的分类类别,如果不止一个类别票数最高,则随机选择一个作为最终类别。
绝对多数投票法
1
稍微复杂些,也就是常说的票过半数,在相对多数投票法的基础上,不仅要求获得最高票,还要求票过半数,否则会拒绝预测,这在可靠性要求较高的学习任务中是一个很好的机制。
加权投票法
1
和加权平均法一样,每个弱学习器的分类票数要乘以一个权重,最终将各类别的加权票数求和,最大值对应的类别为最终类别。