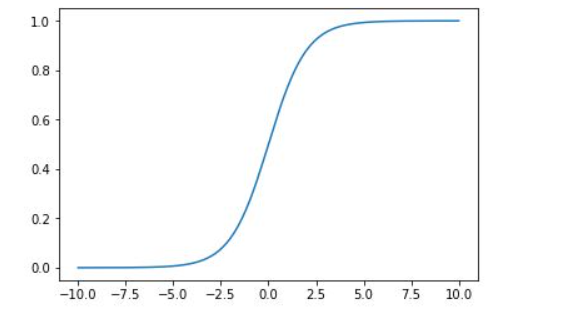
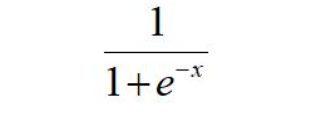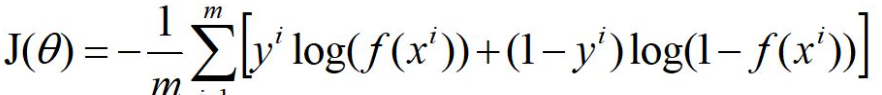逻辑回归 发表于 2019-05-06 字数统计: | 阅读时长 ≈ 逻辑回归基础所以逻辑回归,不是回归,而是分类器,二分类,多分类。 1.使用sigmoid函数,对y的取值进行压缩至[0,1] 图像如下: 2.损失函数真实值与预测值之间的误差的函数,我们希望这个函数越小越好。在这里,最小损失是0。 3.在sklearm中的应用123456789101112131415161718192021222324252627282930sklearn.linear_model.LogisticRegression(penalty=l2, # 惩罚项,可选l1,l2,对参数约束,减少过拟合风险 dual=False, # 对偶方法(原始问题和对偶问题),用于求解线性多核(liblinear)的L2的惩罚项上。样本数大于特征数时设置False tol=0.0001, # 迭代停止的条件,小于等于这个值停止迭代,损失迭代到的最小值。 C=1.0, # 正则化系数λ的倒数,越小表示越强的正则化。 fit_intercept=True, # 是否存在截距值,即b intercept_scaling=1, # class_weight=None, # 类别的权重,样本类别不平衡时使用,设置balanced会自动调整权重。为了平横样本类别比例,类别样本多的,权重低,类别样本少的,权重高。 random_state=None, # 随机种子 solver=’liblinear’, # 优化算法的参数,包括newton-cg,lbfgs,liblinear,sag,saga,对损失的优化的方法 max_iter=100,# 最大迭代次数, multi_class=’ovr’,# 多分类方式,有‘ovr','mvm' verbose=0, # 输出日志,设置为1,会输出训练过程的一些结果 warm_start=False, # 热启动参数,如果设置为True,则下一次训练是以追加树的形式进行(重新使用上一次的调用作为初始化) n_jobs=1 # 并行数,设置为1,用1个cpu运行,设置-1,用你电脑的所有cpu运行程序 )