卷积神经网络基础
1.卷积运算
1.定义

2.动机
卷积运算改进机器学习系统的三个重要思想:
稀疏交互(saprse interactions)
又称稀疏权重(sparse weights),这是因为核大小远小于输入大小。eg:当输入图像包含成千上万像素点,只采用几十个到上百个像素点的和来检测小而有意义的特征。
减少了存取需求,提高统计效率。
参数共享(parameter sharing)
是指,在一个模型中的多个函数中使用相同参数。卷积运算共享一个卷积核,保证我们只需学习一个参数集,而非在每一个位置学习同一个参数集。
等变表示(equivariant represetations)
如果一个函数满足输入改变,而输出也以同样方式改变则该函数是等变的。这在处理时间序列中事件延后,图像序列中对象的移动是非常有利的。
而一些其他的变换在卷积中并非必然。比如图像放缩和旋转变换,则需要其他机制处理。
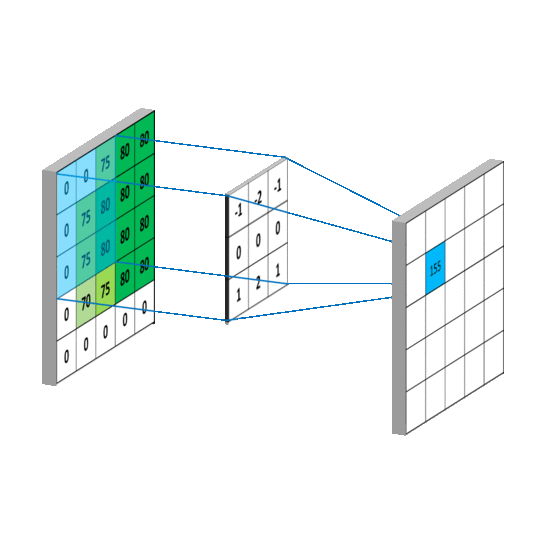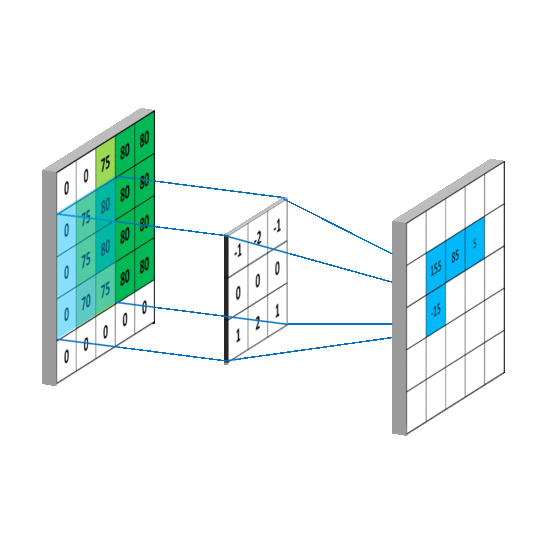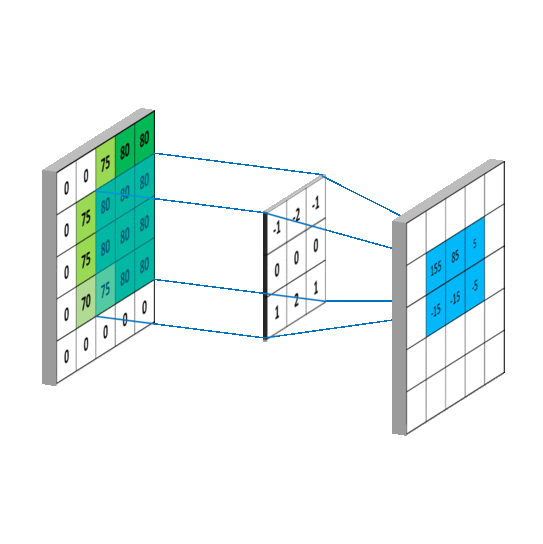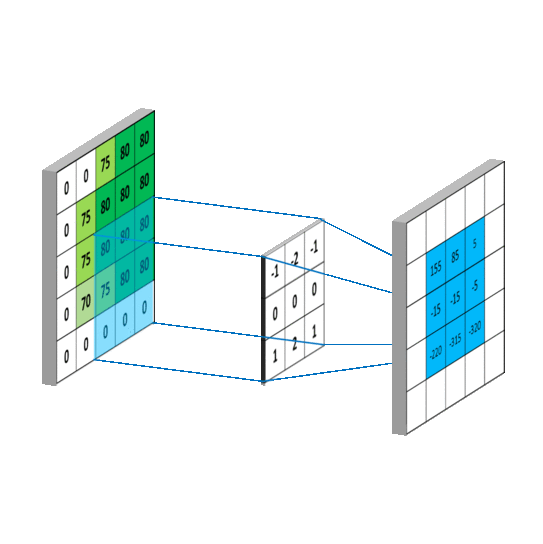
3.一维矩阵运算
在数学里我们知道f(-x)的图像是f(x)对y轴的反转
g(-m)就是把g(m)的序列反转,g(n-m)的意义是把g(-m)平移的n点:
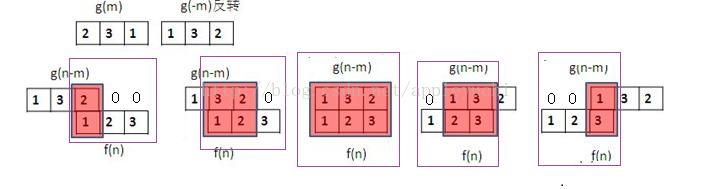
卷积运算时可以交换顺序.
代码实现
1
2
3
4
5
6import numpy as np
x=np.array([1,2,3])
h=np.array([2,3,1])
import scipy.signal
scipy.signal.convolve(x,h)
print(scipy.signal.convolve(x,h))
4.二维矩阵运算
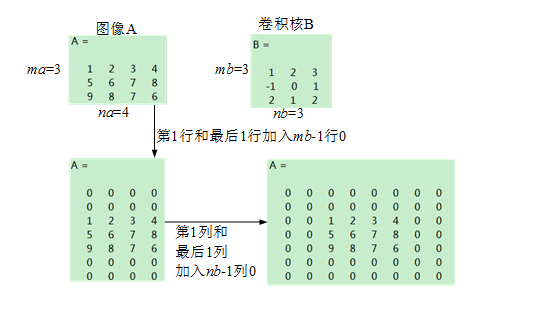
其中,矩阵A和B的尺寸分别为mana即mbnb
① 对矩阵A补零,
第一行之前和最后一行之后都补mb-1行,
第一列之前和最后一列之后都补nb-1列
(注意conv2不支持其他的边界补充选项,函数内部对输入总是补零);
之所以都是-1是因为卷积核要在图像A上面移动,移动的时候需要满足两者至少有一列或者一行是重叠的.
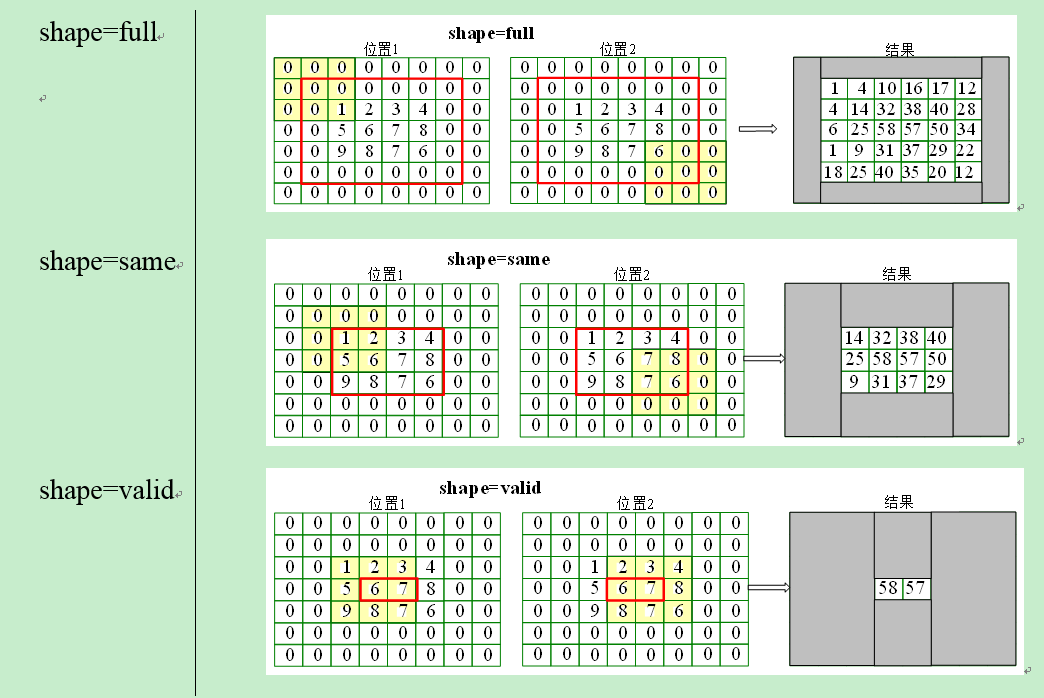
再将卷积核旋转180度,之后有三种计算方式,分别是按照shape=full,shape=same,shape=valid进行计算(重叠部分进行矢量积运算)
卷积层输入特征和输出特征尺寸和卷积核的关系
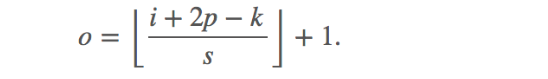
2.反卷积
我们把4×4的输入特征展成[16,1]的矩阵X ,那么Y = CX则是一个[4,1]的输出特征矩阵,把它重新排列2×2的输出特征就得到最终的结果,从上述分析可以看出卷积层的计算其实是可以转化成矩阵相乘的。值得注意的是,在一些深度学习网络的开源框架中并不是通过这种这个转换方法来计算卷积的,因为这个转换会存在很多无用的0乘操作,Caffe中具体实现卷积计算的方法可参考Implementing convolution as a matrix multiplication
通过上述的分析,我们已经知道卷积层的前向操作可以表示为和矩阵C相乘,那么 我们很容易得到卷积层的反向传播就是和C的转置相乘。
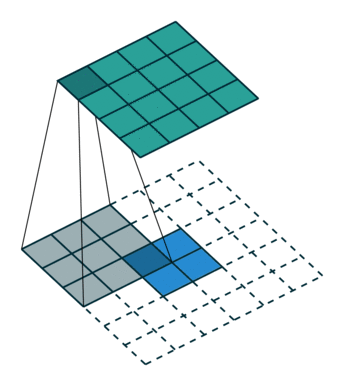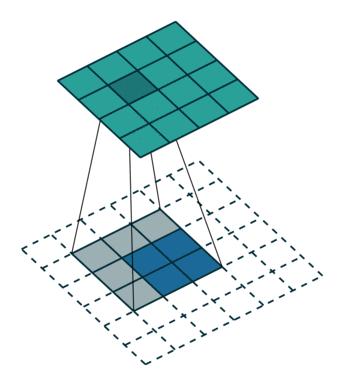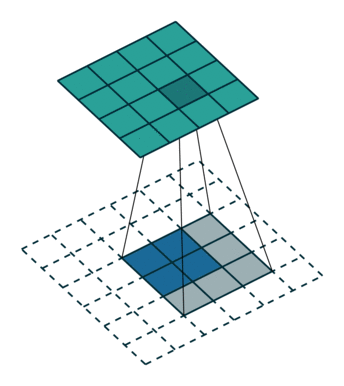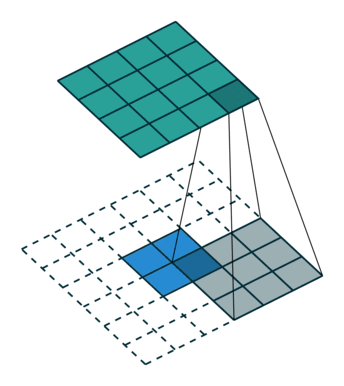
这里提到的反卷积跟1维信号处理的反卷积计算是很不一样的,FCN作者称为backwards convolution,有人称Deconvolution layer is a very unfortunate name and should rather be called a transposed convolutional layer. 我们可以知道,在CNN中有con layer与pool layer,con layer进行对图像卷积提取特征,pool layer对图像缩小一半筛选重要特征,对于经典的图像识别CNN网络,如IMAGENET,最后输出结果是1X1X1000,1000是类别种类,1x1得到的是。FCN作者,或者后来对end to end研究的人员,就是对最终1x1的结果使用反卷积(事实上FCN作者最后的输出不是1X1,是图片大小的32分之一,但不影响反卷积的使用)。
这里图像的反卷积与图6的full卷积原理是一样的,使用了这一种反卷积手段使得图像可以变大,FCN作者使用的方法是这里所说反卷积的一种变体,这样就可以获得相应的像素值,图像可以实现end to end。
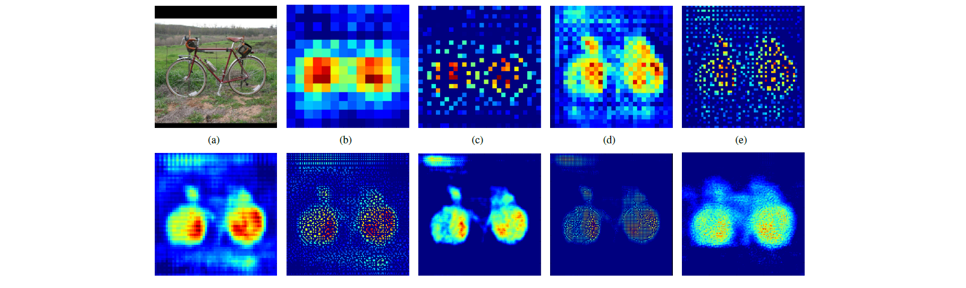
这里说另外一种反卷积做法,假设原图是3X3,首先使用上采样让图像变成7X7,可以看到图像多了很多空白的像素点。使用一个3X3的卷积核对图像进行滑动步长为1的valid卷积,得到一个5X5的图像,我们知道的是使用上采样扩大图片,使用反卷积填充图像内容,使得图像内容变得丰富,这也是CNN输出end to end结果的一种方法。韩国作者Hyeonwoo Noh使用VGG16层CNN网络后面加上对称的16层反卷积与上采样网络实现end to end 输出,其不同层上采样与反卷积变化效果如下:
3.图像卷积的再解释
基本方法(2种):
方法1:full卷积,完整的卷积使得原来的定义变大
方法2:记录pooling index,然后扩大空间
图像的反卷积过程如下:
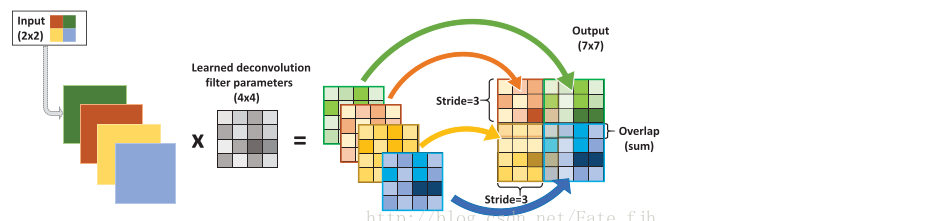
- 输入图片每个像素进行一次full卷积,根据full卷积大小计算可以知道每个像素的卷积后大小为 1+4-1=4, 即4x4大小的特征图,输入有4个像素所以4个4x4的特征图
- 将4个特征图进行步长为3的fusion(即相加); 例如红色的特征图仍然是在原来输入位置(左上角),绿色还是在原来的位置(右上角),步长为3是指每隔3个像素进行fusion,重叠部分进行相加,即输出的第1行第4列是由红色特阵图的第一行第四列与绿色特征图的第一行第一列相加得到,其他如此类推。
2.池化运算
池化层往往在卷积层后面,通过池化来降低卷积层输出的特征向量,同时改善结果(不易出现过拟合)。图像具有一种“静态性”的属性,这也就意味着在一个图像区域有用的特征极有可能在另一个区域同样适用。因此,为了描述大的图像,一个很自然的想法就是对不同位置的特征进行聚合统计,例如,人们可以计算图像一个区域上的某个特定特征的平均值 (或最大值)来代表这个区域的特征
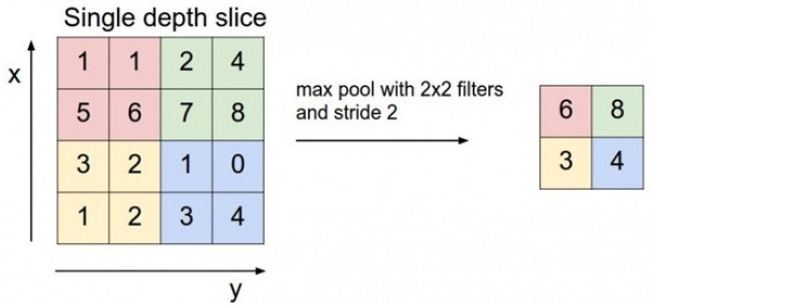
1.Max pooling池化操作
利用CNN卷积神经网络进行训练时,进行完卷积运算,还需要接着进行Max pooling池化操作,目的是在尽量不丢失图像特征前期下,对图像进行downsampling。
整个图片被不重叠的分割成若干个同样大小的小块(pooling size)。每个小块内只取最大的数字,再舍弃其他节点后,保持原有的平面结构得出 output。
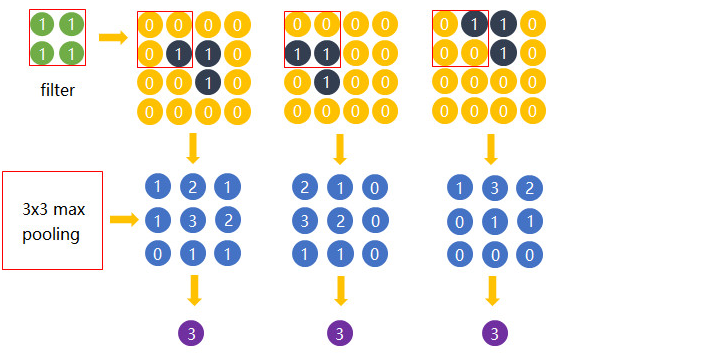
是利用平移不变性
如下面,先进行卷积操作,再进行池化操作:
2.一般池化
池化窗口和窗口移动的距离大小是相等的
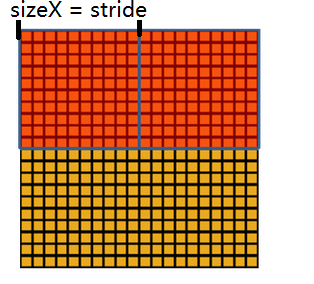
3.重叠池化
重叠池化正如其名字所说的,相邻池化窗口之间会有重叠区域
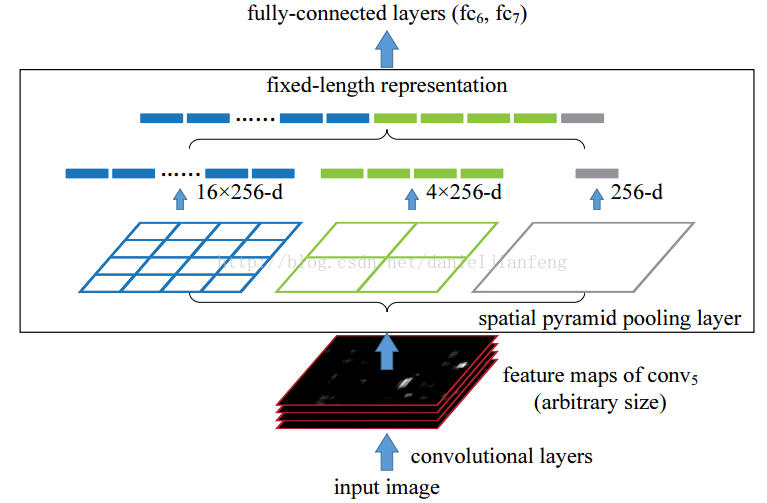
4.空金字塔池化
先让图像进行卷积操作,然后转化成维度相同的特征输入到全连接层,这个可以把CNN扩展到任意大小的图像。

空间金字塔池化的思想来自于Spatial Pyramid Model,它一个pooling变成了多个scale的pooling。用不同大小池化窗口作用于卷积特征,我们可以得到1X1,2X2,4X4的池化结果,由于conv5中共有256个过滤器,所以得到1个256维的特征,4个256个特征,以及16个256维的特征,然后把这21个256维特征链接起来输入全连接层,通过这种方式把不同大小的图像转化成相同维度的特征。
3.Text-CNN原理及文本分类模型
1.原理
具体过程如下
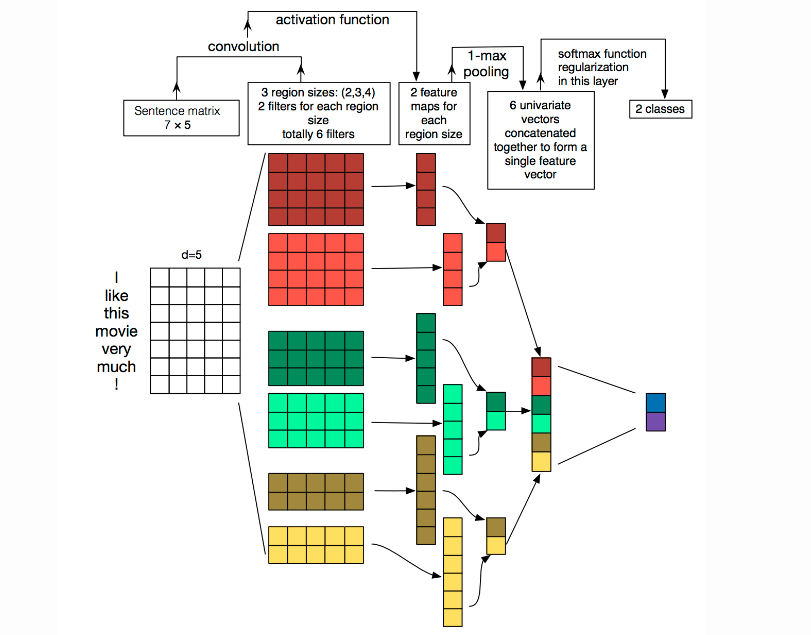
- Embedding:第一层是图中最左边的7乘5的句子矩阵,每行是词向量,维度=5,这个可以类比为图像中的原始像素点。
- Convolution:然后经过 kernel_sizes=(2,3,4) 的一维卷积层,每个kernel_size 有两个输出 channel。
- MaxPolling:第三层是一个1-max pooling层,这样不同长度句子经过pooling层之后都能变成定长的表示。
FullConnection and Softmax:最后接一层全连接的 softmax 层,输出每个类别的概率。
文本是一维数据,因此在TextCNN卷积用的是一维卷积(在word-level上是一维卷积;虽然文本经过词向量表达后是二维数据,但是在embedding-level上的二维卷积没有意义)。一维卷积带来的问题是需要通过设计不同 kernel_size 的 filter 获取不同宽度的视野。
CNN的卷积和池化的过程就是一个抽取特征的过程(摘自CNN原理文本分类)
2004年Yoon Kim 在 “Convolutional Neural Networks for Sentence Classification” 一文中提出(虽然第一个用的并不是他,但是在这篇文章中提出了4种Model Variations,并有详细的调参):
论文使用的模型主要包括五层,第一层是embedding layer,第二层是convolutional layer,第三层是max-pooling layer,第四层是fully connected layer,最后一层是softmax layer.
为了使其可以进行卷积,首先需要将其转化为二维矩阵表示,通常使用word2vec、glove等word embedding实现。d=5表示每个词转化为5维的向量,矩阵的形状是[sentence_matrix × 5],即[7 × 5]。
在处理图像数据时,CNN使用的卷积核的宽度和高度的一样的,但是在text-CNN中,卷积核的宽度是与词向量的维度一致。这是因为我们输入的每一行向量代表一个词,在抽取特征的过程中,词做为文本的最小粒度,如果我们使用卷积核的宽度小于词向量的维度就已经不是以词作为最小粒度了。而高度和CNN一样,可以自行设置(通常取值2,3,4,5)。由于我们的输入是一个句子,句子中相邻的词之间关联性很高,因此,当我们用卷积核进行卷积时,不仅考虑了词义而且考虑了词序及其上下文。(类似于skip-gram和CBOW模型的思想)。
详细讲解卷积的过程:卷积层输入的是一个表示句子的矩阵,维度为n*d,即每句话共有n个词,每个词有一个d维的词向量表示。假设Xi:i+j表示Xi到Xi+j个词,使用一个宽度为d,高度为h的卷积核W与Xi:i+h-1(h个词)进行卷积操作后再使用激活函数激活得到相应的特征ci,则卷积操作可以表示为:(使用点乘来表示卷积操作)
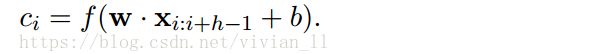
在文本分类中常用的步长是1,更大的补偿会使得向神经网络靠近
窄卷积 vs 宽卷积
在矩阵的中部使用卷积核滤波没有问题,在矩阵的边缘,如对于左侧和顶部没有相邻元素的元素,该如何滤波呢?解决的办法是采用补零法(zero-padding)。所有落在矩阵范围之外的元素值都默认为0。这样就可以对输入矩阵的每一个元素做滤波了,输出一个同样大小或是更大的矩阵。补零法又被称为是宽卷积,不使用补零的方法则被称为窄卷积。
池化:Max-Pooling之后,还需要将每个值给拼接起来。得到池化层最终的特征向量。在池化层到全连接层之前可以加上dropout防止过拟合。
文本中pooling方法的优缺点:
Max Pooling over time
这个操作可以保证特征的位置与旋转不变性,对于图像处理来说这种位置与旋转不变性是很好的特性,但是对于NLP来说,这个特性其实并不一定是好事,因为在很多NLP的应用场合,特征的出现位置信息是很重要的,比如主语出现位置一般在句子头,宾语一般出现在句子尾等等,这些位置信息其实有时候对于分类任务来说还是很重要的,但是Max Pooling 基本把这些信息抛掉了。其次,MaxPooling能减少模型参数数量,有利于减少模型过拟合问题。再者,对于NLP任务来说,Max Pooling可以把变长的输入X整理成固定长度的输入。
但是,CNN模型采取MaxPooling Over Time也有一些值得注意的缺点:首先就如上所述,特征的位置信息在这一步骤完全丢失。在卷积层其实是保留了特征的位置信息的,但是通过取唯一的最大值,现在在Pooling层只知道这个最大值是多少,但是其出现位置信息并没有保留;另外一个明显的缺点是:有时候有些强特征会出现多次,比如我们常见的TF.IDF公式,TF就是指某个特征出现的次数,出现次数越多说明这个特征越强,但是因为Max Pooling只保留一个最大值,所以即使某个特征出现多次,现在也只能看到一次,就是说同一特征的强度信息丢失了。这是Max Pooling Over Time典型的两个缺点。
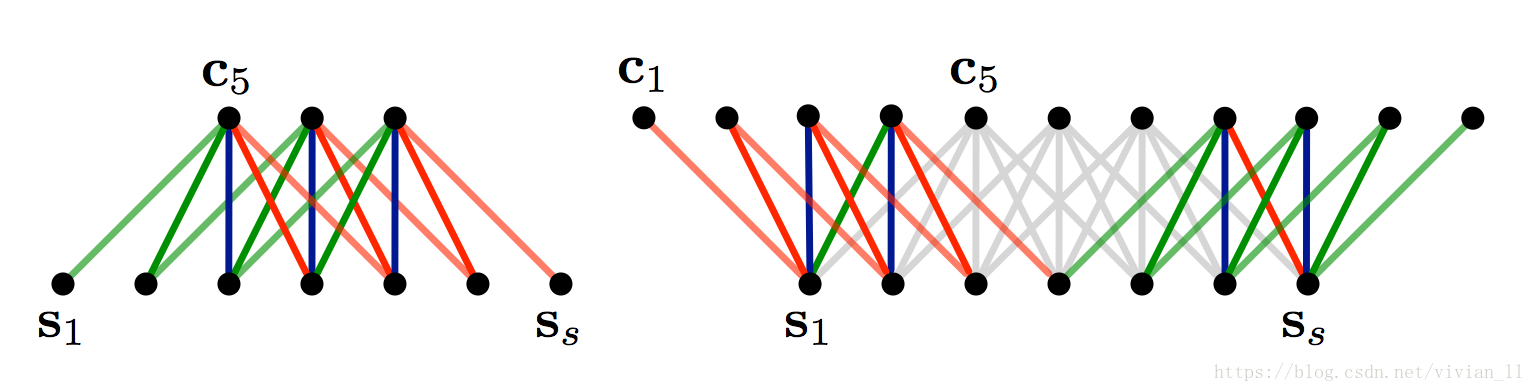
K-Max pooling
取所有特征值中得分在Top –K的值,并保留这些特征值原始的先后顺序(下图是2-max Pooling的示意图),就是说通过多保留一些特征信息供后续阶段使用
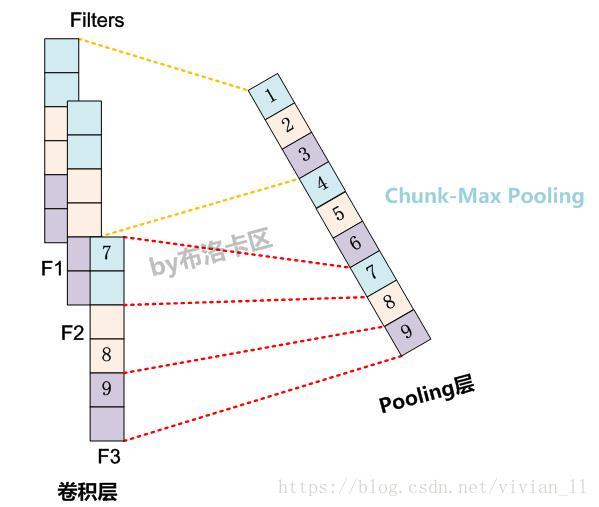
Chunk-Max pooling
Chunk-MaxPooling的思想是:把某个Filter对应的Convolution层的所有特征向量进行分段,切割成若干段后,在每个分段里面各自取得一个最大特征值,比如将某个Filter的特征向量切成3个Chunk,那么就在每个Chunk里面取一个最大值,于是获得3个特征值。(如下图所示,不同颜色代表不同分段)
全连接层跟其他模型一样,假设有两层全连接层,第一层可以加上relu作为激活函数,对于多分类来说,第二层则使用softmax激活函数得到属于每个类的概率,并选择categorical_crossentropy 作为激活函数。如果处理的数据集为二分类问题,如情感分析的正负面时,第二层也可以使用sigmoid作为激活函数,然后损失函数使用对数损失函数binary_crossentropy。
*将不同的词向量表征看成是不同的通道:
- CNN-rand: 随机初始化每个单词的词向量通过后续的训练去调整。
- CNN-static: 使用预先训练好的词向量,如word2vec训练出来的词向量,在训练过程中不再调整该词向量。
- CNN-non-static: 使用预先训练好的词向量,并在训练过程进一步进行调整。
- CNN-multichannel: 将static与non-static作为两通道的词向量。