简单神经网络(2)
1.词袋模型(bow : 离散、高维、稀疏)
在自然语言处理和文本分析的问题中,词袋(Bag of Words, BOW)和词向量(Word Embedding)是两种最常用的模型。更准确地说,词向量只能表征单个词,如果要表示文本,需要做一些额外的处理。所谓BOW,就是将文本/Query看作是一系列词的集合。
- 离散:无法衡量词向量之间的关系, 比如酒店、宾馆、旅社 三者都只在某一个固定的位置为 1 ,所以找不到三者的关系,各种度量(与或非、距离)都不合适,即太稀疏,很难捕捉到文本的含义。
高维:词表维度随着语料库增长膨胀,n-gram 序列随语料库膨胀更快。
数据稀疏: 数据都没有特征多,数据有 100 条,特征有 1000 个
举个例子:
文本1:苏宁易购/是/国内/著名/的/B2C/电商/之一
这是一个短文本。“/”作为词与词之间的分割。从中我们可以看到这个文本包含“苏宁易购”,“B2C”,“电商”等词。换句话说,该文本的的词袋由“苏宁易购”,“电商”等词构成。就像这样:

但计算机不认识字,只认识数字,那在计算机中怎么表示词袋模型呢?其实很简单,给每个词一个位置/索引就可以了。例如,我们令“苏宁易购”的索引为0,“电商”的索引为1,其他以此类推。则该文本的词袋就变成了:
词袋是在词集的基础上增加了频率的维度,词集只关注有和没有,词袋还要关注有几个。
假设我们要对一篇文章进行特征化,最常见的方式就是词袋。
假如现在有1000篇新闻文档,把这些文档拆成一个个的字,去重后得到3000个字,然后把这3000个字作为字典,进行文本表示的模型,叫做词袋模型。这种模型的特点是字典中的字没有特定的顺序,句子的总体结构也被舍弃了.
- 2.分布式表示(连续,稠密,低维)
分布式(distributed)描述的是把
信息分布式地存储在向量的各个维度中,与之相对的是局部表示(local
representation),如词的独热表示(one-hot representation),在高维向量中
只有一个维度描述了词的语义。一般来说,通过矩阵降维或神经网络降维
可以将语义分散存储到向量的各个维度中,因此,这类方法得到的低维向 量一般都可以称作分布式表示。
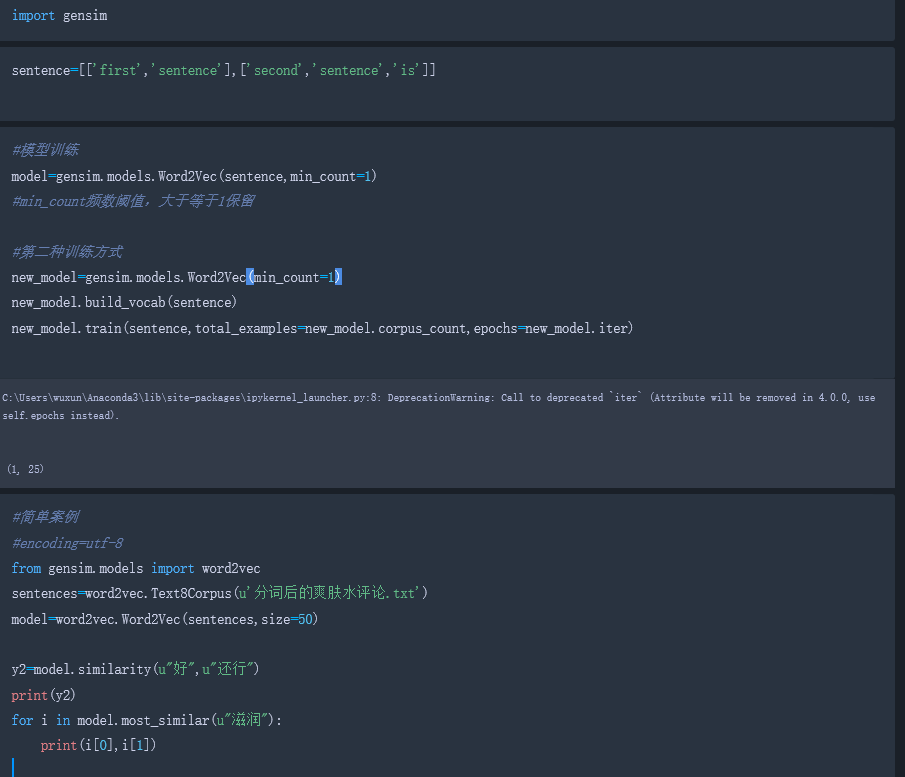
2.word2vec代码实现
3.bow2vec + TFIDF模型
主要内容为:
拆分句子为单词颗粒,记号化;
生成词典;
生成稀疏文档矩阵
1 | documents = ["Human machine interface for lab abc computer applications", |
tfidf
1 | #生成词袋 |