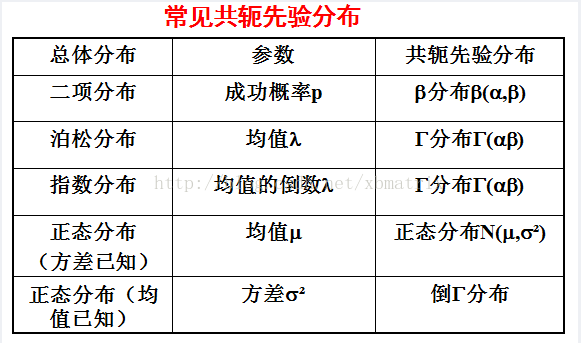
1.共轭先验分布
共轭先验分布的提出:某观测数据服从概率分布p(θ),当观测到新的数据时,思考下列问题:
1.能否根据新观测数据X更新参数θ;
2.根据新观测的数据可以在多大的程度上改变参数θ:θ=θ+rθ;
3.当重新估计得到θ时,给出的新参数数值θ的新概率分布p(θ|x);
分析:根据贝叶斯公式:p(θ|x)=p(x|θ)p(θ)
p(x),其中p(x|θ)是在已知θ的情况下估计x的概率分布,又称似然函数;p(θ)是原有的θ的概率分布;要想利用观测到的数据更新参数θ,就要使更新后的p(θ|x)和p(θ)服从相同的分布,所以p(θ)和p(θ|x)形成共轭分布,p(θ)叫做p(θ|x)的共轭先验分布。
举个投硬币的例子:使用参数θ的伯努利模型,θ为正面的概率,则结果为x的概率分布为:p(x|θ)=θx(1−θ)1-x
在贝叶斯概率理论中,如果后验概率P(θ|X)和先验概率P(θ)满足同样的分布律(形式相同,参数不同)。那么,先验分布和后验分布被叫做共轭分布,同时,先验分布叫做似然函数的共轭先验分布。
2.pLSA
LSA是处理这类问题的著名技术。其主要思想就是映射高维向量到潜在语义空间,使其降维。LSA的目标就是要寻找到能够很好解决实体间词法和语义关系的数据映射。正是由于这些特性,使得LSA成为相当有价值并被广泛应用的分析工具。PLSA是以统计学的角度来看待LSA,相比于标准的LSA,他的概率学变种有着更巨大的影响。
概率潜在语义分析(pLSA) 基于双模式和共现的数据分析方法延伸的经典的统计学方法。
概率潜在语义分析应用于信息检索,过滤,自然语言处理,文本的机器学习或者其他相关领域。概率潜在语义分析与标准潜在语义分析的不同是,标准潜在语义分析是以共现表(就是共现的矩阵)的奇异值分解的形式表现的,而概率潜在语义分析却是基于派生自LCM的混合矩阵分解。考虑到word和doc共现形式,概率潜在语义分析基于多项式分布和条件分布的混合来建模共现的概率。所谓共现其实就是W和D的一个矩阵,所谓双模式就是在W和D上同时进行考虑。
PLSA有时会出现过拟合的现象。所谓过拟合(Overfit),是这样一种现象:一个假设在训练数据上能够获得比其他假设更好的拟合,但是在训练数据外的数据集上却不能很好的拟合数据。此时我们就叫这个假设出现了overfit的现象。出现这种现象的主要原因是训练数据中存在噪音或者训练数据太少。
解决办法,要避免过拟合的问题,PLSA使用了一种广泛应用的最大似然估计的方法,期望最大化。PLSA中训练参数的值会随着文档的数目线性递增。PLSA可以生成其所在数据集的的文档的模型,但却不能生成新文档的模型。
数学推导待补充(看不懂…..)
3.LDA主题模型原理
待补充(看不懂…..)
4.LDA参数学习–Gibbs采样训练流程
- 选择合适的主题数K,选择合适的超参数α、η;
- 对于语料库中每一篇文档的每一个词,随机的赋予一个主题编号z;
- 重新扫描语料库,对于每一个词,利用Gibbs采样公式更新它的topic的编号,并更新语料库中该词的编号。
- 重复第三步中基于坐标轴轮询的Gibbs采样,直到Gibbs采样收敛。
- 统计语料库中各个文档各个词的主题,得到文档主题分布
5.LDA生成主题特征,在之前的特征的基础上加入主题特征实现文本分类
1.先来了解数据集
数据集位于lda安装目录的tests文件夹中,包含三个文件:reuters.ldac, reuters.titles, reuters.tokens。
reuters.titles包含了395个文档的标题
reuters.tokens包含了这395个文档中出现的所有单词,总共是4258个
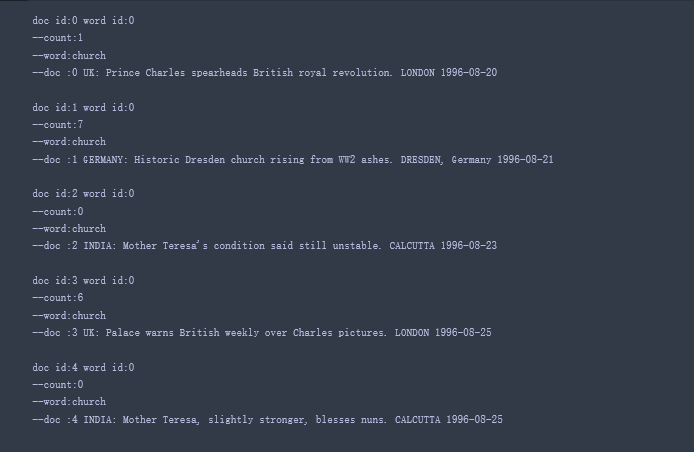
reuters.ldac有395行,第i行代表第i个文档中各个词汇出现的频率。以第0行为例,第0行代表的是第0个文档,从reuters.titles中可查到该文档的标题为“UK: Prince Charles spearheads British royal revolution. LONDON 1996-08-20”。
第0行的数据为:
159 0:1 2:1 6:1 9:1 12:5 13:2 20:1 21:4 24:2 29:1 ……
第一个数字159表示第0个文档里总共出现了159个单词(每个单词出现一或多次),
0:1表示第0个单词出现了1次,从reuters.tokens查到第0个单词为church
2:1表示第2个单词出现了1次,从reuters.tokens查到第2个单词为years
6:1表示第6个单词出现了1次,从reuters.tokens查到第6个单词为told
9:1表示第9个单词出现了1次,从reuters.tokens查到第9个单词为year
12:5表示第12个单词出现了5次,从reuters.tokens查到第12个单词为charles
……
这里第1、3、4、5、7、8、10、11……个单词序号和次数没列出来,表示出现的次数为0
注意:
395个文档的原文是没有的。上述三个文档是根据这395个文档处理之后得到的。
2代码实现
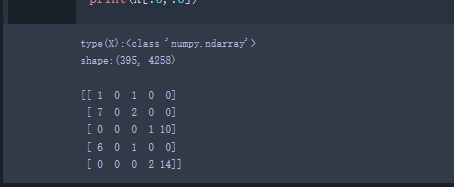
1 | #查看文本中词出先的频率 |
1 | #查看词 |

1 | #查看文档标题 |

1 | #查看前五个文档第0个词出现的次数 |
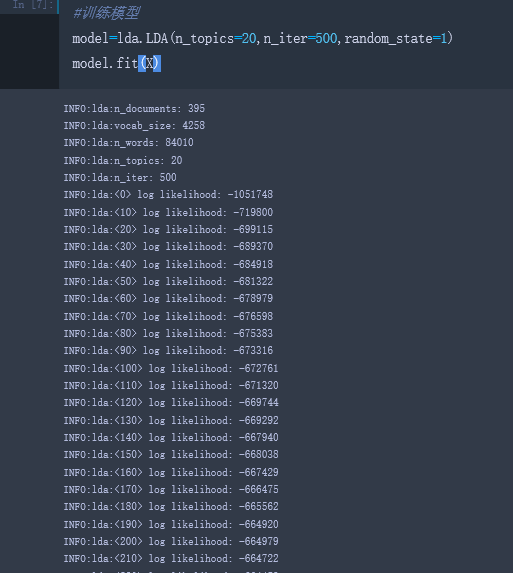
1 | #训练模型 |
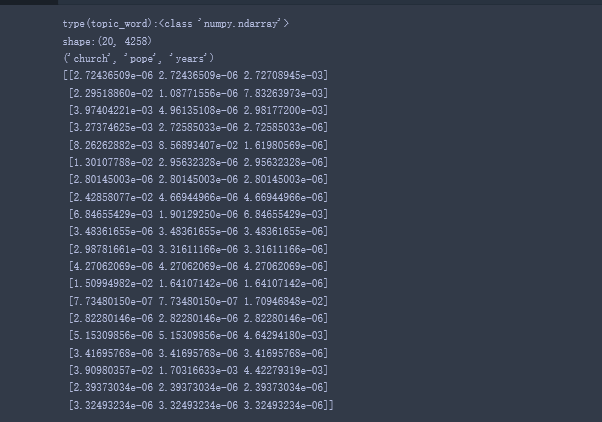
#主题-单词分布
#计算前三个单词在所有的主题中所占的权重
topic_word=model.topic_word_
print(“type(topic_word):{}”.format(type(topic_word)))
print(“shape:{}”.format(topic_word.shape))
print(vocab[:3])
print(topic_word[:,:3])
1 | #计算所有行的比重之和 |
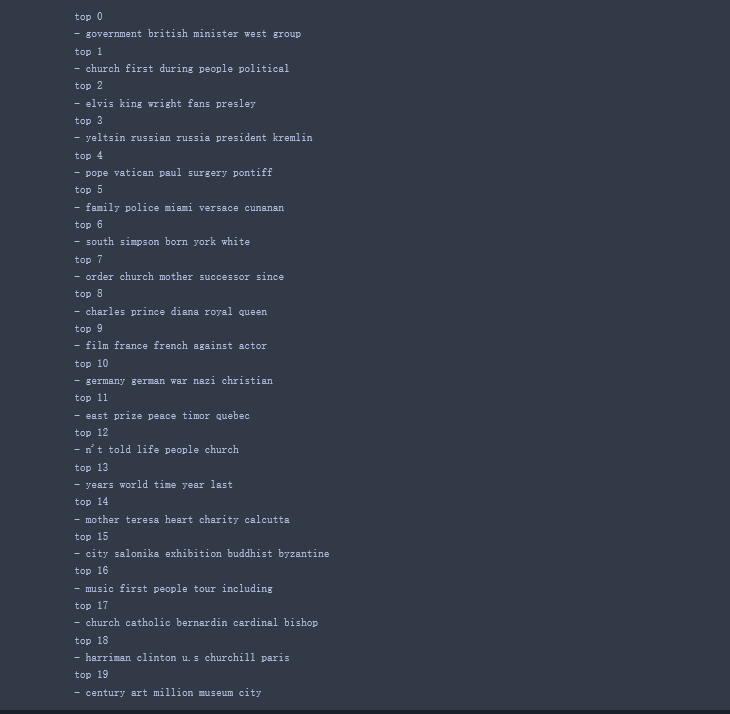
1 | #计算各个主题的topN个词 |
1 | #计算前十篇文章最有可能的主题 |

1 | #可视化分析 |
