支持向量机(SVM)原理及应用
1.算法原理
1.简介
支持向量机(support vector machines)是一种二分类模型,它的目的是寻找一个超平面来对样本进行分割,分割的原则是间隔最大化,最终转化为一个凸二次规划问题来求解。由简至繁的模型包括:
- 当训练样本线性可分时,通过硬间隔最大化,学习一个线性可分支持向量机;
- 当训练样本近似线性可分时,通过软间隔最大化,学习一个线性支持向量机;
- 当训练样本线性不可分时,通过核技巧和软间隔最大化,学习一个非线性支持向量机;
2. 线性可分的支持向量机
基本的想法就是基于训练集D在样本空间中找到一个划分超平面,将不同类别的样本分开。训练集标签为yi={1|-1}
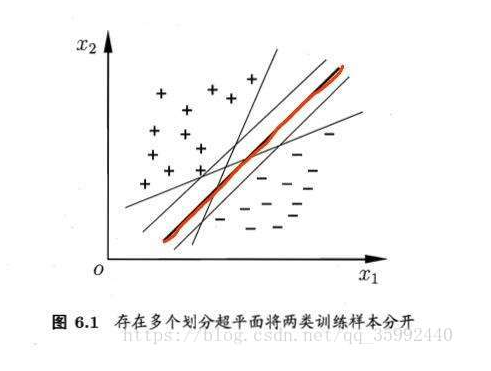
直观看上去,能将训练样本分开的划分超平面有很多,但应该去找位于两类训练样本“正中间”的划分超平面,即图6.1中红色的那条,因为该划分超平面对训练样本局部扰动的“容忍”性最好,例如,由于训练集的局限性或者噪声的因素,训练集外的样本可能比图6.1中的训练样本更接近两个类的分隔界,这将使许多划分超平面出现错误。而红色超平面的影响最小,简言之,这个划分超平面所产生的结果是鲁棒性的。
那什么是线性可分呢?
如果一个线性函数能够将样本分开,称这些数据样本是线性可分的。那么什么是线性函数呢?其实很简单,在二维空间中就是一条直线,在三维空间中就是一个平面,以此类推,如果不考虑空间维数,这样的线性函数统称为超平面。我们看一个简单的二维空间的例子,O代表正类,X代表负类,样本是线性可分的,但是很显然不只有这一条直线可以将样本分开,而是有无数条,我们所说的线性可分支持向量机就对应着能将数据正确划分并且间隔最大的直线。
在实际应用总,我们所要求解的是能将数据正确划分的并且间隔最大的超平面
一个点距离超平面的远近可以表示分类的确信度,,距离超平面更远的点确信度更高,求解最号的SVM时,我们不许考录所有点,只要让超平面距离较近的点的点间隔最大即可
距离超平面最近的几个点成为“支持向量”,两条虚线的距离称为 * 间隔 *
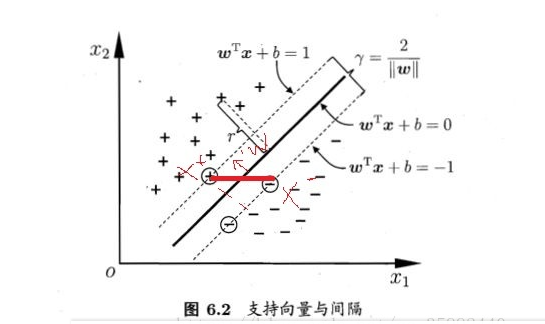
间隔的计算:两个异类支持向量在实现的法线方向的投影大小
3.非线性支持向量机和核函数
待补充
4.线性支持向量机(软间隔支持向量机)与松弛变量
待补充
2.SVM优缺点
优点:
1、使用核函数可以向高维空间进行映射
2、使用核函数可以解决非线性的分类
3、分类思想很简单,就是将样本与决策面的间隔最大化
4、分类效果较好
缺点:
1、对大规模数据训练比较困难
2、无法直接支持多分类,但是可以使用间接的方法来做
3.SVM应用场景
SVM在很多数据集上都有优秀的表现。
相对来说,SVM尽量保持与样本间距离的性质导致它抗攻击的能力更强。
和随机森林一样,这也是一个拿到数据就可以先尝试一下的算法
4.SVM sklearn参数学习
1 | class sklearn.svm.SVC( |
- SVC class
sklearn.svm.`SVC`(C=1.0, kernel=’rbf’, degree=3, gamma=’auto’, coef0=0.0, shrinking=True, probability=False, tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape=’ovr’, random_state=None)
**C:**惩罚系数,用来控制损失函数的惩罚系数,类似于LR中的正则化系数。C越大,相当于惩罚松弛变量,希望松弛变量接近0,即对误分类的惩罚增大,趋向于对训练集全分对的情况,这样会出现训练集测试时准确率很高,但泛化能力弱,容易导致过拟合。 C值小,对误分类的惩罚减小,容错能力增强,泛化能力较强,但也可能欠拟合。
**kernel:**算法中采用的和函数类型,核函数是用来将非线性问题转化为线性问题的一种方法。参数选择有RBF, Linear, Poly, Sigmoid,precomputed或者自定义一个核函数, 默认的是”RBF”,即径向基核,也就是高斯核函数;而Linear指的是线性核函数,Poly指的是多项式核,Sigmoid指的是双曲正切函数tanh核;。
degree: 当指定kernel为’poly’时,表示选择的多项式的最高次数,默认为三次多项式;若指定kernel不是’poly’,则忽略,即该参数只对’poly’有用。(多项式核函数是将低维的输入空间映射到高维的特征空间)
**gamma:**核函数系数,该参数是rbf,poly和sigmoid的内核系数;默认是’auto’,那么将会使用特征位数的倒数,即1 / n_features。(即核函数的带宽,超圆的半径)。gamma越大,σ越小,使得高斯分布又高又瘦,造成模型只能作用于支持向量附近,可能导致过拟合;反之,gamma越小,σ越大,高斯分布会过于平滑,在训练集上分类效果不佳,可能导致欠拟合。
**coef0:**核函数常数值(y=kx+b中的b值),只有‘poly’和‘sigmoid’核函数有,默认值是0。
shrinking : 是否进行启发式。如果能预知哪些变量对应着支持向量,则只要在这些样本上训练就够了,其他样本可不予考虑,这不影响训练结果,但降低了问题的规模并有助于迅速求解。进一步,如果能预知哪些变量在边界上(即a=C),则这些变量可保持不动,只对其他变量进行优化,从而使问题的规模更小,训练时间大大降低。这就是Shrinking技术。 Shrinking技术基于这样一个事实:支持向量只占训练样本的少部分,并且大多数支持向量的拉格朗日乘子等于C。
probability: 是否使用概率估计,默认是False。必须在 fit( ) 方法前使用,该方法的使用会降低运算速度。
**tol:**残差收敛条件,默认是0.0001,即容忍1000分类里出现一个错误,与LR中的一致;误差项达到指定值时则停止训练。
**cache_size:**缓冲大小,用来限制计算量大小,默认是200M。
class_weight : {dict, ‘balanced’},字典类型或者’balance’字符串。权重设置,正类和反类的样本数量是不一样的,这里就会出现类别不平衡问题,该参数就是指每个类所占据的权重,默认为1,即默认正类样本数量和反类一样多,也可以用一个字典dict指定每个类的权值,或者选择默认的参数balanced,指按照每个类中样本数量的比例自动分配权值。如果不设置,则默认所有类权重值相同,以字典形式传入。 将类i 的参数C设置为SVC的class_weight[i]C。如果没有给出,所有类的weight 为1。’balanced’模式使用y 值自动调整权重,调整方式是与输入数据中类频率成反比。如n_samples / (n_classes np.bincount(y))。(给每个类别分别设置不同的惩罚参数C,如果没有给,则会给所有类别都给C=1,即前面参数指出的参数C。如果给定参数’balance’,则使用y的值自动调整与输入数据中的类频率成反比的权重。)
verbose : 是否启用详细输出。在训练数据完成之后,会把训练的详细信息全部输出打印出来,可以看到训练了多少步,训练的目标值是多少;但是在多线程环境下,由于多个线程会导致线程变量通信有困难,因此verbose选项的值就是出错,所以多线程下不要使用该参数。
**max_iter:**最大迭代次数,默认是-1,即没有限制。这个是硬限制,它的优先级要高于tol参数,不论训练的标准和精度达到要求没有,都要停止训练。
decision_function_shape : 原始的SVM只适用于二分类问题,如果要将其扩展到多类分类,就要采取一定的融合策略,这里提供了三种选择。‘ovo’ 一对一,为one v one,即将类别两两之间进行划分,用二分类的方法模拟多分类的结果,决策所使用的返回的是(样本数,类别数*(类别数-1)/2); ‘ovr’ 一对多,为one v rest,即一个类别与其他类别进行划分,返回的是(样本数,类别数),或者None,就是不采用任何融合策略。默认是ovr,因为此种效果要比oro略好一点。
random_state: 在使用SVM训练数据时,要先将训练数据打乱顺序,用来提高分类精度,这里就用到了伪随机序列。如果该参数给定的是一个整数,则该整数就是伪随机序列的种子值;如果给定的就是一个随机实例,则采用给定的随机实例来进行打乱处理;如果啥都没给,则采用默认的 np.random实例来处理。
NuSVC class
sklearn.svm.`NuSVC`(nu=0.5, kernel=’rbf’, degree=3, gamma=’auto’, coef0=0.0, shrinking=True, probability=False, tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape=’ovr’, random_state=None)nu: 训练误差部分的上限和支持向量部分的下限,取值在(0,1)之间,默认是0.5
LinearSVC class
sklearn.svm.`LinearSVC`(penalty=’l2’, loss=’squared_hinge’, dual=True, tol=0.0001, C=1.0, multi_class=’ovr’, fit_intercept=True, intercept_scaling=1, class_weight=None, verbose=0, random_state=None, max_iter=1000)
**penalty:**正则化参数,L1和L2两种参数可选,仅LinearSVC有。
**loss:**损失函数,有‘hinge’和‘squared_hinge’两种可选,前者又称L1损失,后者称为L2损失,默认是是’squared_hinge’,其中hinge是SVM的标准损失,squared_hinge是hinge的平方
**dual:**是否转化为对偶问题求解,默认是True。
**tol:**残差收敛条件,默认是0.0001,与LR中的一致。
**C:**惩罚系数,用来控制损失函数的惩罚系数,类似于LR中的正则化系数。
**multi_class:**负责多分类问题中分类策略制定,有‘ovr’和‘crammer_singer’ 两种参数值可选,默认值是’ovr’,’ovr’的分类原则是将待分类中的某一类当作正类,其他全部归为负类,通过这样求取得到每个类别作为正类时的正确率,取正确率最高的那个类别为正类;‘crammer_singer’ 是直接针对目标函数设置多个参数值,最后进行优化,得到不同类别的参数值大小
**fit_intercept:**是否计算截距,与LR模型中的意思一致。
**class_weight:**与其他模型中参数含义一样,也是用来处理不平衡样本数据的,可以直接以字典的形式指定不同类别的权重,也可以使用balanced参数值。
**verbose:**是否冗余,默认是False。
**random_state:**随机种子。
**max_iter:**最大迭代次数,默认是1000。
SVM结合TF-IDF原理进行文本分类
1 | # -*- coding: utf-8 -*- |