朴素贝叶斯算法
朴素贝叶斯法(Naive Bayes)是基于贝叶斯定理与特征条件独立假设的分类方法。对于给定的训练数据集,首先基于特征条件独立假设学习输入/输出的联合概率分布;然后基于此模型,对给定的输入 xx ,利用贝叶斯定理求出后验概率最大的输出 yy 。
可能读完上面这段话仍旧没办法理解朴素贝叶斯法到底是什么,又是怎样进行分类的。下面我尽可能详细且直观地描述朴素贝叶斯法的工作原理。首先我们需要知道的是,朴素贝叶斯是基于概率论的分类算法。
1. 朴素贝叶斯
朴素贝叶斯被认为是最简单的分类算法之一。首先,我们需要了解一些概率论的基本理论。假设有两个随机变量X和Y,他们分别可以取值为x和y。有这两个随机变量,我们可以定义两种概率:
关键概念:联合概率与条件概率
联合概率:“X取值为x”和“Y取值为y”两个事件同时发生的概率,表示为P(X=x,Y=y)P(X=x,Y=y) P(X = x, Y = y)P(X=x,Y=y)
条件概率:在X取值为x的前提下,Y取值为y的概率,表示为P(Y=y∣X=x)P(Y=y∣X=x) P(Y = y | X = x)P(Y=y∣X=x)
在概率论中,我们可以证明,两个事件的联合概率等于这两个事件任意条件概率 * 这个条件事件本身的概率。
P(X=1,Y=1)=P(Y=1∣X=1)∗P(X=1)=P(X=1∣Y=1)∗P(Y=1)P(X=1,Y=1)=P(Y=1∣X=1)∗P(X=1)=P(X=1∣Y=1)∗P(Y=1) P(X = 1, Y = 1) =P(Y = 1|X = 1)*P(X=1)=P(X = 1|Y=1)*P(Y=1)P(X=1,Y=1)=P(Y=1∣X=1)∗P(X=1)=P(X=1∣Y=1)∗P(Y=1)
简单一些,则可以将上面的式子写成:
P(X,Y)=P(Y∣X)∗P(X)=P(X∣Y)∗P(Y)P(X,Y)=P(Y∣X)∗P(X)=P(X∣Y)∗P(Y) P(X, Y)=P(Y|X)*P(X)=P(X|Y)*P(Y)P(X,Y)=P(Y∣X)∗P(X)=P(X∣Y)∗P(Y)
由上面的式子,我们可以得到贝叶斯理论等式:
P(Y∣X)=P(X∣Y)∗P(Y)P(X)P(Y∣X)=P(X∣Y)∗P(Y)P(X) P(Y|X) = \frac{P(X|Y)*P(Y)}{P(X)}P(Y∣X)=P(X)P(X∣Y)∗P(Y)
而这个式子,就是我们一切贝叶斯算法的根源理论。我们可以把我们的特征XX XX当成是我们的条件事件,而我们要求解的标签YY YY当成是我们被满足条件后会被影响的结果,而两者之间的概率关系就是P(Y∣X)P(Y∣X) P(Y|X)P(Y∣X),这个概率在机器学习中,被我们称之为是标签的后验概率(posterior probability),即是说我们先知道了条件,再去求解结果。而标签 在没有任何条件限制下取值为某个值的概率,被我们写作P(Y)P(Y) P(Y)P(Y),与后验概率相反,这是完全没有任何条件限制的,标签的先验概率(prior probability)。而我们的P(X∣Y)P(X∣Y) P(X|Y)P(X∣Y) 被称为“类的条件概率”,表示当Y的取值固定的时候,X为某个值的概率。
3.朴素贝叶斯公式的推导

2.贝叶斯估计

3.朴素贝叶斯算法的过程

使用朴素贝叶斯进行文本分类示例
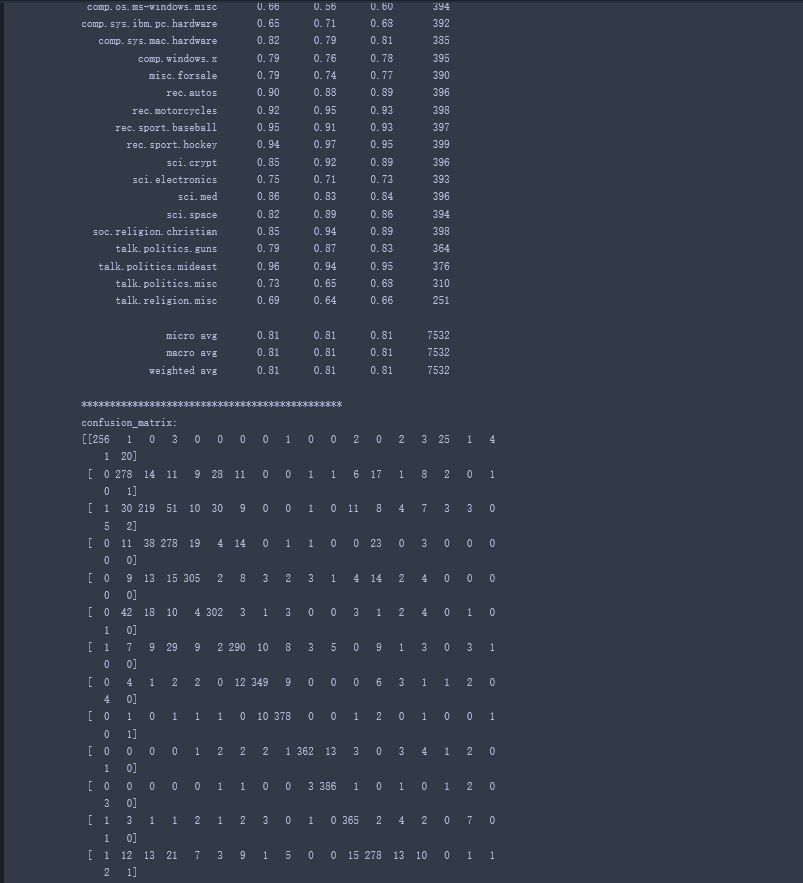
本次使用的数据集来自于业内著名的20 Newsgroups 数据集,包含20类标注好的样本,数据量共计约2万条记录。该数据集每篇文档均不长,即使同时使用多个类目数据合并起来进行建模,在单机上也可快速完成,因此具有很好的学习训练价值。
1 | from time import time |
结果输出:

1 |
|

1 |
|

1 | #加载测试集合 |
1 |
|

1 |
|