k邻近算法的原理和使用
1.算法原理
1. KNN算法三要素
KNN算法我们主要要考虑三个重要的要素,对于固定的训练集,只要这三点确定了,算法的预测方式也就决定了。这三个最终的要素是k值的选取,距离度量的方式和分类决策规则。
- 对于分类决策规则,一般都是使用前面提到的多数表决法。所以我们重点是关注与k值的选择和距离的度量方式。
- 对于k值的选择,没有一个固定的经验,一般根据样本的分布,选择一个较小的值,可以通过交叉验证选择一个合适的k值。
- 选择较小的k值,就相当于用较小的领域中的训练实例进行预测,训练误差会减小,只有与输入实例较近或相似的训练实例才会对预测结果起作用,与此同时带来的问题是泛化误差会增大,换句话说,K值的减小就意味着整体模型变得复杂,容易发生过拟合;
- 选择较大的k值,就相当于用较大领域中的训练实例进行预测,其优点是可以减少泛化误差,但缺点是训练误差会增大。这时候,与输入实例较远(不相似的)训练实例也会对预测器作用,使预测发生错误,且K值的增大就意味着整体的模型变得简单。
- 一个极端是k等于样本数m,则完全没有分类,此时无论输入实例是什么,都只是简单的预测它属于在训练实例中最多的类,模型过于简单。
- 对于距离的度量,我们有很多的距离度量方式,但是最常用的是欧式距离。
2.核心思想
计算待标记的数据样本和数据集中的每个样本的距离,取距离最近的K个样本,待标记的数据样本就由这k个距离最近的样本投票产生
算法原理的伪代码
- 遍历x_train中的所有样本,计算每个样本与X_test的距离,并吧距离保存在Distance数组中
- 对Distance数组进行排序,取距离最近的k个点,即为X_knn
- 对X-knn中统计每个类别的个数,即在class0在X_knn中有几个样本,class1在X_knn中有几个样本…..
- 待标记的样本类别,就是在X_knn中样本个数最多的那个类别。
3.算法优缺点
- 优点:准确性高,对异常值和噪声有较高的容忍度
- 缺点:计算量大,对内存需求大
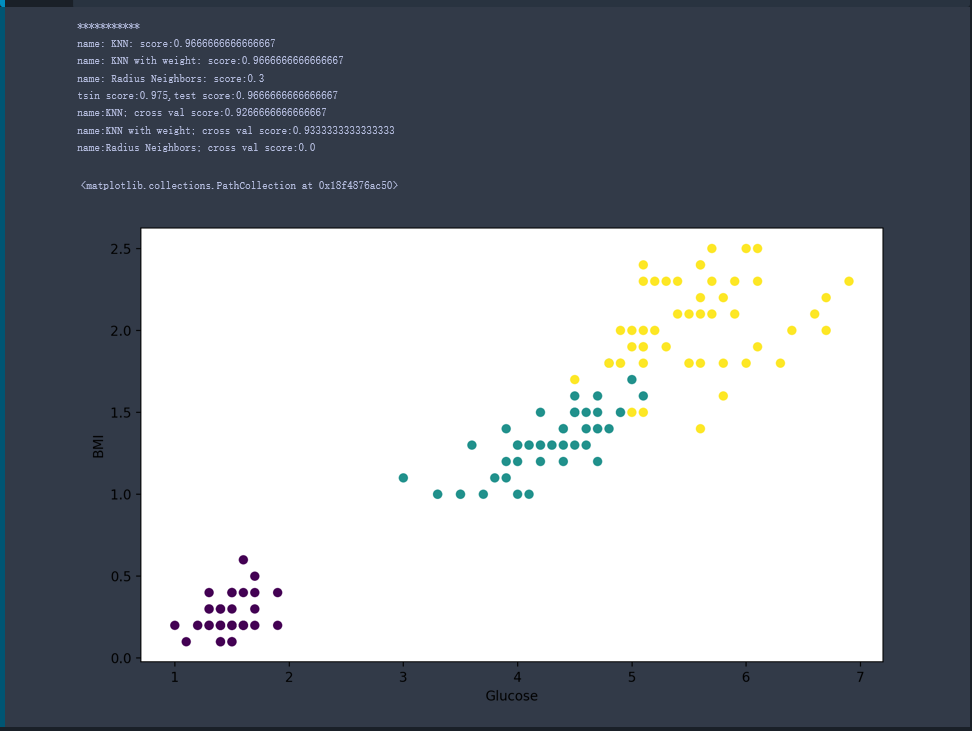
2.简单运用(使用k邻近算法进行分类)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35from sklearn.datasets.samples_generator import make_blobs
from matplotlib import pyplot as plt
import numpy as np
#生成数据
centers=[[-2,2],[2,2],[0,4]]
X,y=make_blobs(n_samples=600,centers=centers,random_state=0,cluster_std=0.6)
#画出数据
plt.figure(figsize=(16,10),dpi=144)
c=np.array(centers)
plt.scatter(X[:,0],X[:,1],cmap='cool',c=y,s=100)
plt.scatter(c[:,0],c[:,1],s=100,marker='^',c='orange')
#调用训练器来进行分类
from sklearn.neighbors import KNeighborsClassifier
k=5
#训练模型
clf=KNeighborsClassifier()
clf.fit(X,y)
#预测
X_sample=[[0,2]]
y_sample=clf.predict(X_sample)
neighbors=clf.kneighbors(X_sample,return_distance=False)
#画出该点和临近点
print(X_sample)
print(neighbors)
print(X_sample[0][0])
plt.scatter(X_sample[0][0],X_sample[0][1],c="red",s=100)
for i in neighbors[0]:
#print(X[i][0])
plt.plot([X[i][0],X_sample[0][0]],[X[i][1],X_sample[0][1]],'k--',linewidth=0.8);
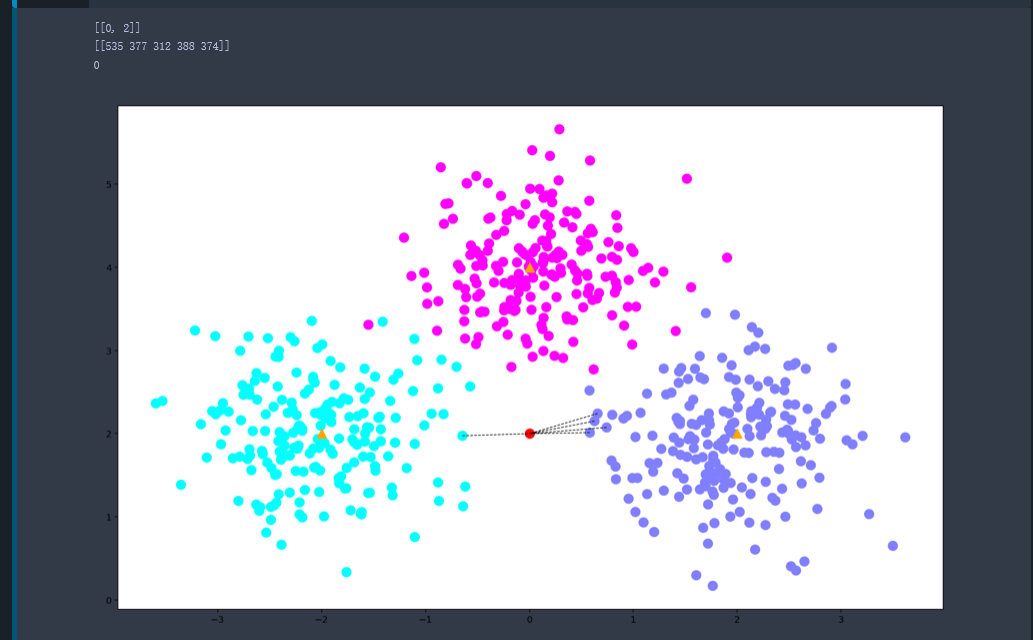
3.示例运用(使用k邻近算法进行回归拟合)
1 | #生成数据集 |
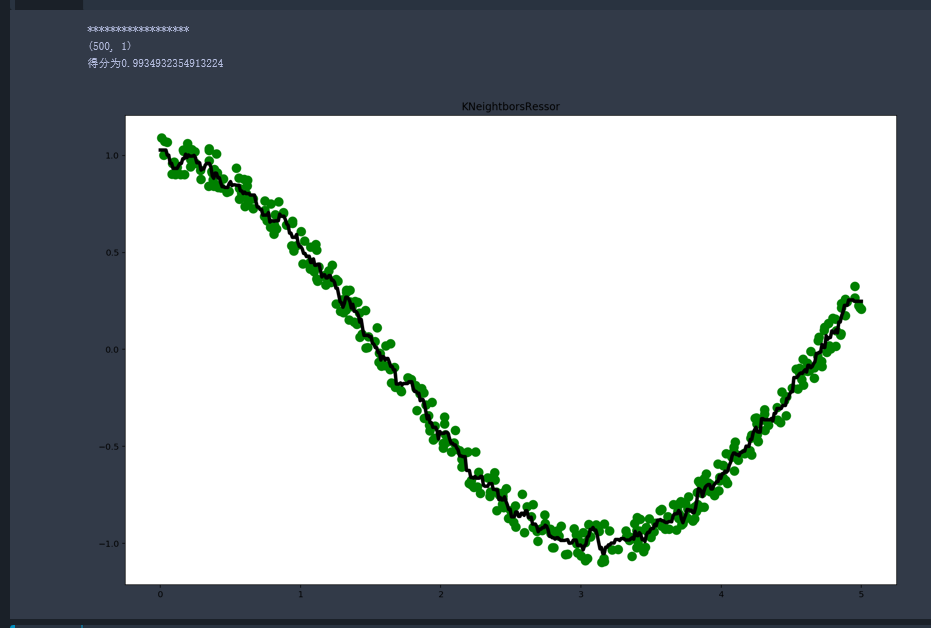
4.实际运用
1 | from sklearn import datasets |