1.召回率和查全率
召回率(Recall Rate,也叫查全率,是检索出的相关文档数和文档库中所有的相关文档数的比率,衡量的是检索系统的查全率,精度是检索出的相关文档数与检索出的文档总数的比率,衡量的是检索系统查准率。
召回率(Recall)和精度(Precise)是广泛用于信息检索和统计学分类领域的两个度量值,用来评价结果的质量。
1.ROC曲线
1、roc曲线:接收者操作特征(receiveroperating characteristic),roc曲线上每个点反映着对同一信号刺激的感受性。
横轴:负正类率(false postive rate FPR)特异度,划分实例中所有负例占所有负例的比例;(1-Specificity)
纵轴:真正类率(true postive rate TPR)灵敏度,Sensitivity(正类覆盖率)
机器学习中常用的指标量
TP:正确的肯定数目
FN:漏报,没有找到正确匹配的数目
FP:误报,没有的匹配不正确
TN:正确拒绝的非匹配数目
由上表可得出横,纵轴的计算公式:
(1)真正类率(True Postive Rate)TPR: TP/(TP+FN),代表分类器预测的正类中实际正实例占所有正实例的比例。Sensitivity
(2)负正类率(False Postive Rate)FPR: FP/(FP+TN),代表分类器预测的正类中实际负实例占所有负实例的比例。1-Specificity
(3)真负类率(True Negative Rate)TNR: TN/(FP+TN),代表分类器预测的负类中实际负实例占所有负实例的比例,TNR=1-FPR。Specificity
AUC(Area under Curve):Roc曲线下的面积,介于0.1和1之间。Auc作为数值可以直观的评价分类器的好坏,值越大越好。
首先AUC值是一个概率值,当你随机挑选一个正样本以及负样本,当前的分类算法根据计算得到的Score值将这个正样本排在负样本前面的概率就是AUC值,AUC值越大,当前分类算法越有可能将正样本排在负样本前面,从而能够更好地分类。
3. 为什么使用Roc 和Auc评价分类器
既然已经这么多标准,为什么还要使用ROC和AUC呢?因为ROC曲线有个很好的特性:当测试集中的正负样本的分布变换的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现样本类不平衡,即正负样本比例差距较大,而且测试数据中的正负样本也可能随着时间变化。
4.PR曲线
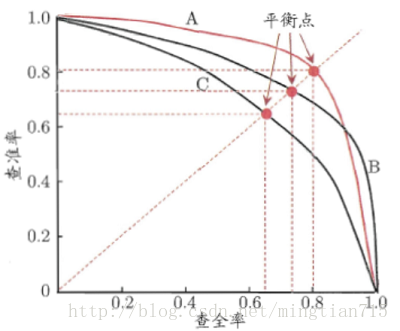
P-R曲线刻画查准率和查全率之间的关系,查准率指的是在所有预测为正例的数据中,真正例所占的比例,查全率是指预测为真正例的数据占所有正例数据的比例。
即:查准率P=TP/(TP + FP) 查全率=TP/(TP+FN)
查准率和查全率是一对矛盾的度量,一般来说,查准率高时,查全率往往偏低,查全率高时,查准率往往偏低,例如,若希望将好瓜尽可能多选出来,则可通过增加选瓜的数量来实现,如果希望将所有的西瓜都选上,那么所有的好瓜必然都被选上了,但这样查准率就会较低;若希望选出的瓜中好瓜比例尽可能高,则可只挑选最有把握的瓜,但这样就难免会漏掉不少好瓜,使得查全率较低。
在很多情况下,我们可以根据学习器的预测结果对样例进行排序,排在前面的是学习器认为最可能是正例的样本,排在后面的是学习器认为最不可能是正例的样本,按此顺序逐个把样本作为正例进行预测,则每次可计算当前的查全率和查准率,以查准率为y轴,以查全率为x轴,可以画出下面的P-R曲线。
5.IMDB影评数据集
该数据下载后包含train和test两个文件夹和三个文件,其中test文件夹中的两个文件夹pos和neg分别为1.25W个代表积极和消极态度的训练样本。而train中的三个文件夹pos、neg、unsup分别为1.25W代表积极和消极态度的训练样本以及5W个未标记的样本。未标记样本可以用来作无监督学习时使用。
THUCnews数据集
THUCNews是根据新浪新闻RSS订阅频道2005~2011年间的历史数据筛选过滤生成,包含74万篇新闻文档(2.19 GB),均为UTF-8纯文本格式。我们在原始新浪新闻分类体系的基础上,重新整合划分出14个候选分类类别:财经、彩票、房产、股票、家居、教育、科技、社会、时尚、时政、体育、星座、游戏、娱乐